Holdout 验证
Holdout 验证 (Holdout Validation) 是一种广泛使用的模型验证方法,将数据集划分为不同的集合,一部分用于训练,另一部分用于测试。
数据集划分:训练集和测试集
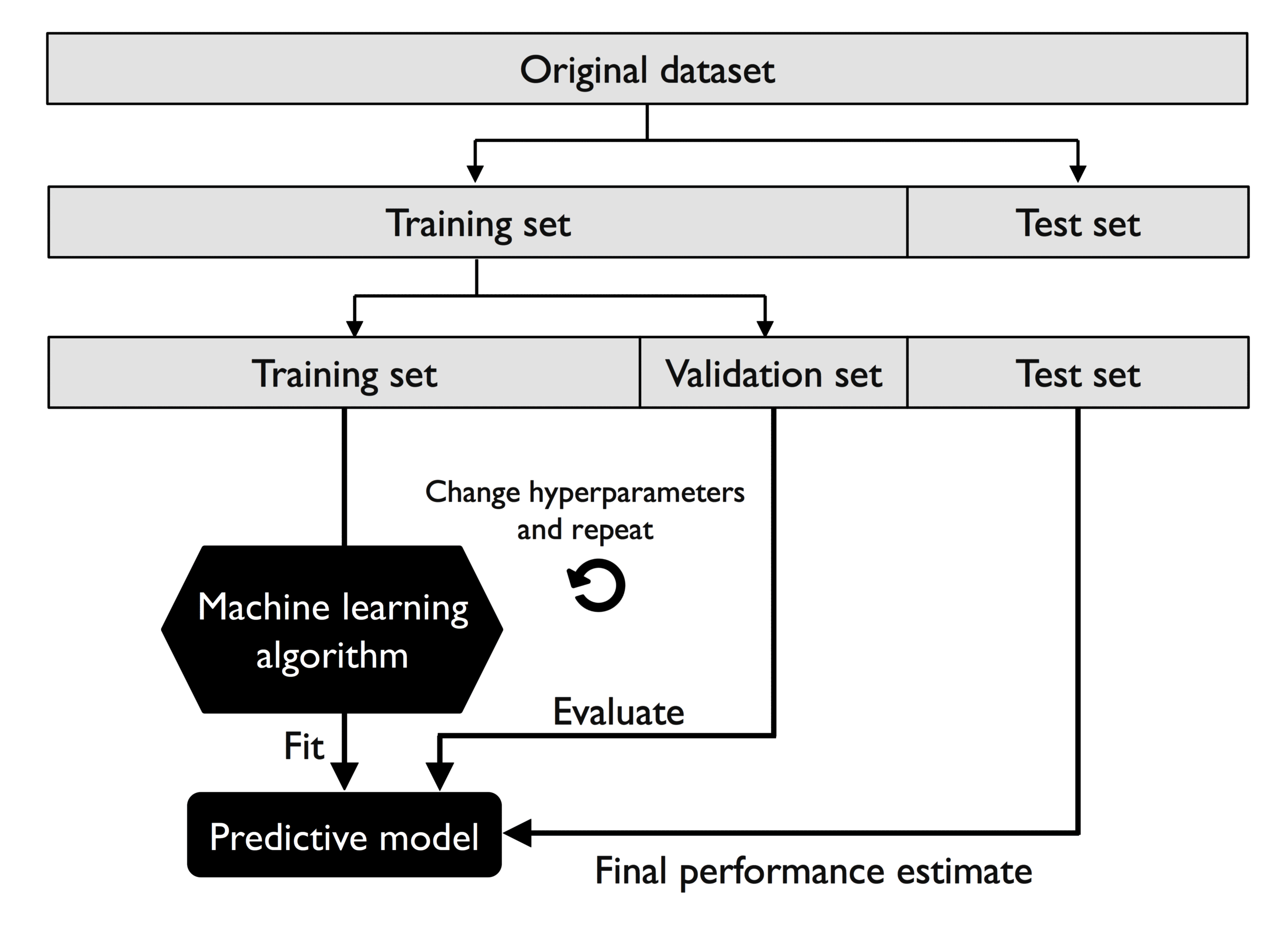
对于评估机器学习模型的泛化性能,一种经典和普遍的方法是 holdout 交叉验证。holdout 方法将初始数据集分成单独的训练集 (Training Set) 和测试集 (Test Set),前者用于模型训练,后者用于评估模型的泛化性能。在典型的机器学习程序中,人们会对超参数进行不断调整和比较,以进一步提高对不可见数据进行预测的性能。这个过程被称为模型选择 (Model Selection),尝试将超参数调整至最优。
但是,如果在模型选择过程中重复使用相同的测试集,那么这个测试集就不是真正意义上的测试集。真正的测试集应该是不可见的。如果一直尝试对测试集拟合,这个测试集实际上就是训练集的一部分。
尽管如此,许多人仍然将数据集分为测试集和训练集,然后按照测试集的表现来进行模型选择。这不是一个良好的机器学习方法。
数据集划分:训练集、验证集和测试集
一种更好的模型选择方法是将数据分成三部分:训练集、验证集 (Validation Set) 和测试集。训练集用于拟合不同的模型,然后根据模型在验证集上的表现来进行模型选择。在整个训练过程中,测试集是不可见的,不会对测试集过拟合。
下图说明了保持交叉验证的概念,使用训练集和验证集进行反复训练并将超参数调整至较优水平,再使用测试集来评估模型的泛化性能:
Holdout 方法的缺点是算法评估对数据划分比较敏感,对于不同的数据划分比例和不同的分布,评估结果可能会有较大差异。