K 折交叉验证
K 折交叉验证 (K-Fold Cross-Validation) 是一种模型选择 (Model Selection) 方法,将初始样本分为 K 个折叠 (Fold),一个折叠作为数据集、其余 K-1 个折叠作为训练集,反复重复上述步骤 K 次并将得到的结果综合起来,得到最终的评估结果。K 折交叉验证在一定程度上解决了 holdout 只划分数据一次的缺点。
K 折交叉验证原理
K 折交叉验证的步骤是,随机地将训练数据集分成 K 次折叠。其中 K-1 次折叠用于模型训练、另外一个折叠用于性能评估,上述步骤重复 K 次 (每次抽取不同的折叠),获得 K 个模型的性能评估结果。
K 折交叉验证可以得到令人满意的泛化性能的最优超参数值,具有更高的准确率和鲁棒性。K 折交叉验证表现好的原因在于其拥有更多的训练样本,且每个训练样本都恰好验证一次,这样可以产生较低的方差。
下图说明了详细的 K 折交叉验证 (K = 10) 的流程,其中 test fold 实际上发挥的是验证集的作用:
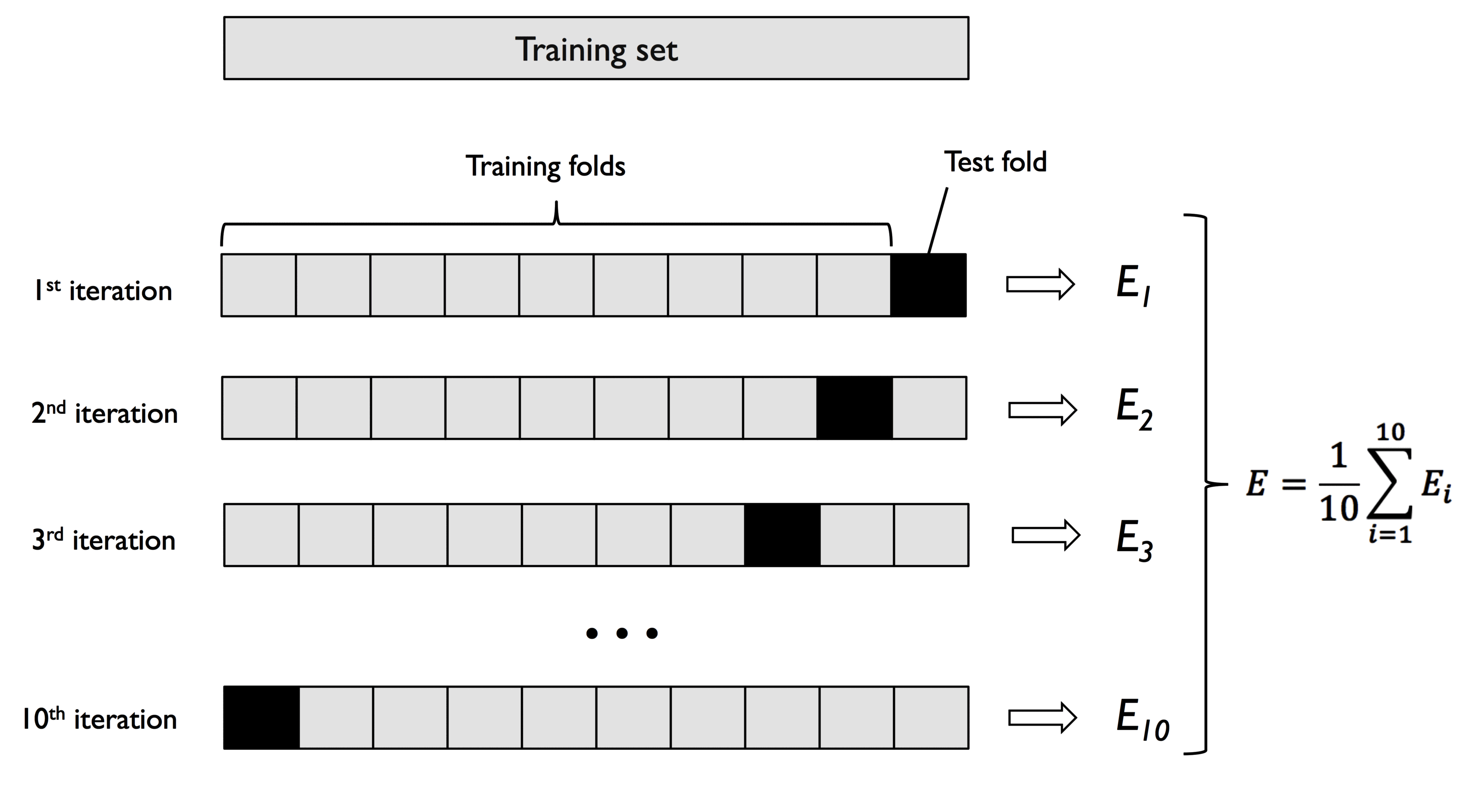
根据以往研究人员的经验,超参数 K 一般推荐采用 10。如果 K 太小,方差会较高,如果 K 太大,模型的训练时间会变长。对于大型数据集,可以适当降低 K 的值 (如 K = 5)。
一种特殊的 K 折交叉验证为留一验证 (Leave-One-Out Cross-Validation,LOOCV),K = n (n 为数据集的样本数量),每折只有一个样本,可以用于处理小数据集。
分层 K 折交叉验证的 scikit-learn 实现
分层 K 折交叉验证 (Stratified K-Fold Cross-Validation) 是对 K 折交叉验证的改进,分层的意思是每一个折叠中的分类比例都与原始数据集相同,能更好地适用于不同分类的样本数差异较大的情况。下面基于 scikit-learn 中的进行说明。
先做好交叉验证之前的前提工作,其中 pipe_lr 是管道对象,封装了标准化、PCA 和逻辑回归:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header=None,
)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, stratify=y, random_state=1
)
pipe_lr = make_pipeline(
StandardScaler(), PCA(n_components=2), LogisticRegression(random_state=1)
)
使用 sklearn.model_selection.StratifiedKFold 进行 K 折分层交叉验证:
import numpy as np
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits=10, random_state=1).split(X_train, y_train)
scores = []
for k, (train, test) in enumerate(kfold):
pipe_lr.fit(X_train[train], y_train[train])
score = pipe_lr.score(X_train[test], y_train[test])
scores.append(score)
print('Fold: {:2d}, Class dist.: {}, Acc: {:.3f}'.format(k + 1, np.bincount(y_train[train]), score)
将样本分为 n_splits=10 个折叠,在每一次循环中使用管道对象 pipe_lr 对测试集进行训练,然后观察训练后的模型在验证集上的准确率。运行结果如下:
Fold: 1, Class dist.: [256 153], Acc: 0.935
Fold: 2, Class dist.: [256 153], Acc: 0.935
Fold: 3, Class dist.: [256 153], Acc: 0.957
Fold: 4, Class dist.: [256 153], Acc: 0.957
Fold: 5, Class dist.: [256 153], Acc: 0.935
Fold: 6, Class dist.: [257 153], Acc: 0.956
Fold: 7, Class dist.: [257 153], Acc: 0.978
Fold: 8, Class dist.: [257 153], Acc: 0.933
Fold: 9, Class dist.: [257 153], Acc: 0.956
Fold: 10, Class dist.: [257 153], Acc: 0.956
计算 10 次训练的准确率的平均值和方差:
print("CV accuracy: {:.3f} +/- {:.3f}".format(np.mean(scores), np.std(scores)))
# Output: CV accuracy: 0.950 +/- 0.014
上面是通过具体实现流程说明交叉验证的工作流程,也可以通过 sklearn.model_selection.cross_val_score 实现模型评估:
scores = cross_val_score(estimator=pipe_lr, X=X_train, y=y_train, cv=10, n_jobs=1)
print("CV accuracy scores: {}".format(scores))
print("CV accuracy: {:.3f} +/- {:.3f}".format(np.mean(scores), np.std(scores)))
其中 cv 为折叠数量,n_jobs 是代码运行使用 CPU 核心的数量,结果如下:
CV accuracy scores: [ 0.93478261 0.93478261 0.95652174 0.95652174 0.93478261 0.95555556
0.97777778 0.93333333 0.95555556 0.95555556]
CV accuracy: 0.950 +/- 0.014
结果与之前一致,采用 cross_val_score 可以非常便捷地对交叉验证模型进行评估。
嵌套交叉验证
嵌套交叉验证 (Nested Cross-Validation) 算法具有更稳定的性能,在训练集上的结果相对于测试集几乎是无偏的。
其思想是先使用 K 折交叉验证将数据分为训练折叠和测试折叠,然后在训练折叠内部使用 K 折交叉验证后用于测试折叠,以选择最优模型。如下为 5×2 折叠交叉验证的示意图:
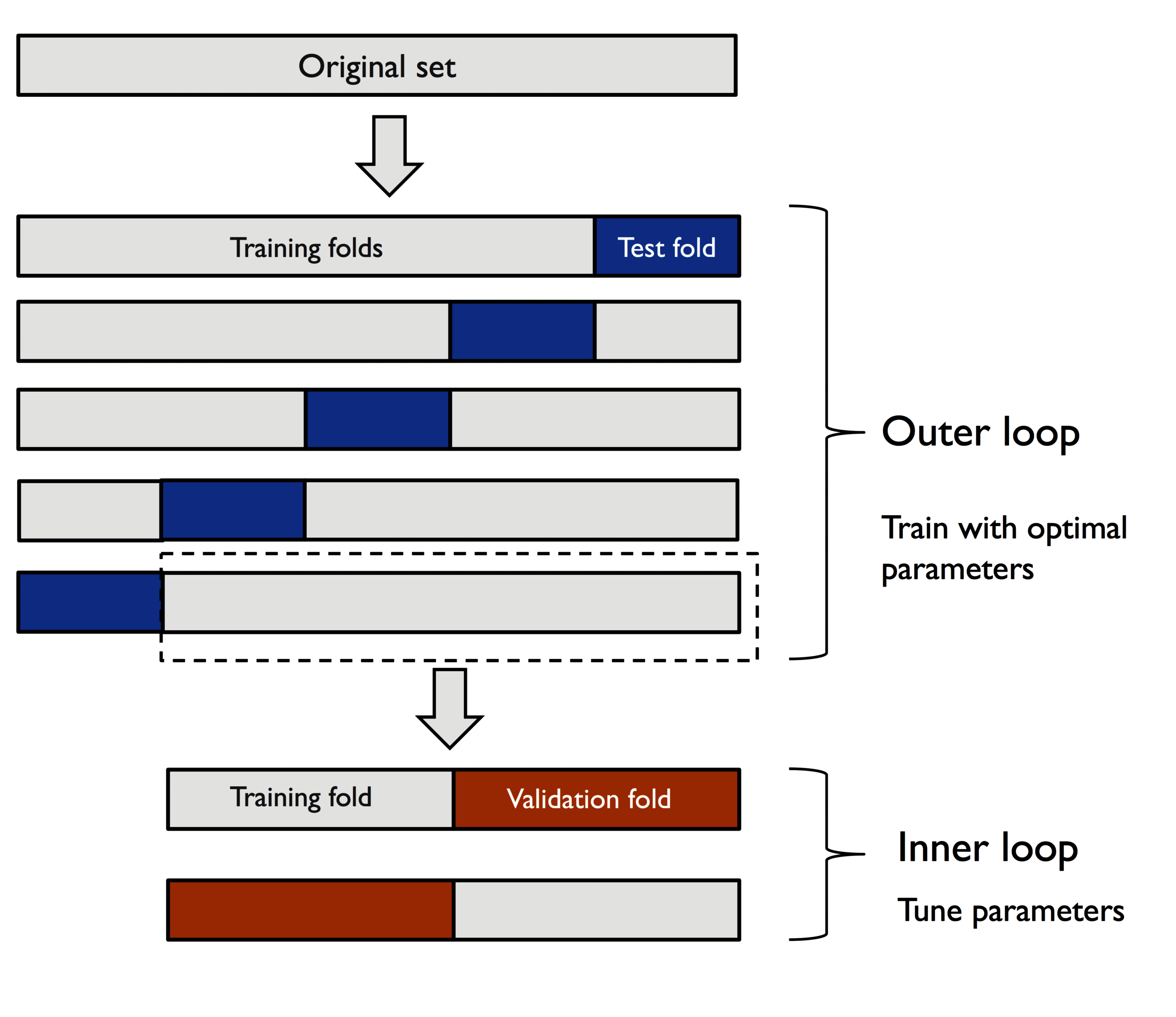
基于 SVM 的 5×2 折叠交叉验证,实现如下:
gs = GridSearchCV(estimator=pipe_svc, param_grid=param_grid, scoring="accuracy", cv=2)
scores = cross_val_score(gs, X_train, y_train, scoring="accuracy", cv=5)
print("CV accuracy: {:.3f} +/- {:.3f}".format(np.mean(scores), np.std(scores)))
# Output: CV accuracy: 0.974 +/- 0.015
基于决策树的 5×2 折叠交叉验证,实现如下:
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(
estimator=DecisionTreeClassifier(om_state=0),
param_grid=[{"max_depth": [1, 2, 3, 4, 5, 6, 7, None]}],
scoring="accuracy",
cv=2,
)
scores = cross_val_score(gs, X_train, y_train, scoring="accuracy", cv=5)
print("CV accuracy: %.3f +/- %.3f" % (np.mean(scores), np.std(scores)))
# Output: CV accuracy: 0.934 +/- 0.016
可以看到,基于 SVM 模型的嵌套交叉验证相比于基于决策树的交叉验证更优。