混淆矩阵
评估指标 (Evaluation Metrics) 除了准确率 (Accuracy) 之外,还有其他的一些指标,如精确率 (Precision)、召回率 (Recall) 和 F1 分数 (F1 Score) 等。它们是混淆矩阵中的评估指标。
混淆矩阵的概念
在介绍不同评分指标的评估指标之前,先介绍混淆矩阵 (Confusion Matrix):
- TP (True Positives):预测为正、实际为正的样本数
- FN (False Negatives):预测为负、实际为正的样本数
- FP (False Positives):预测为正、实际为负的样本数
- TN (True Negatives):预测为负、实际为负的样本数
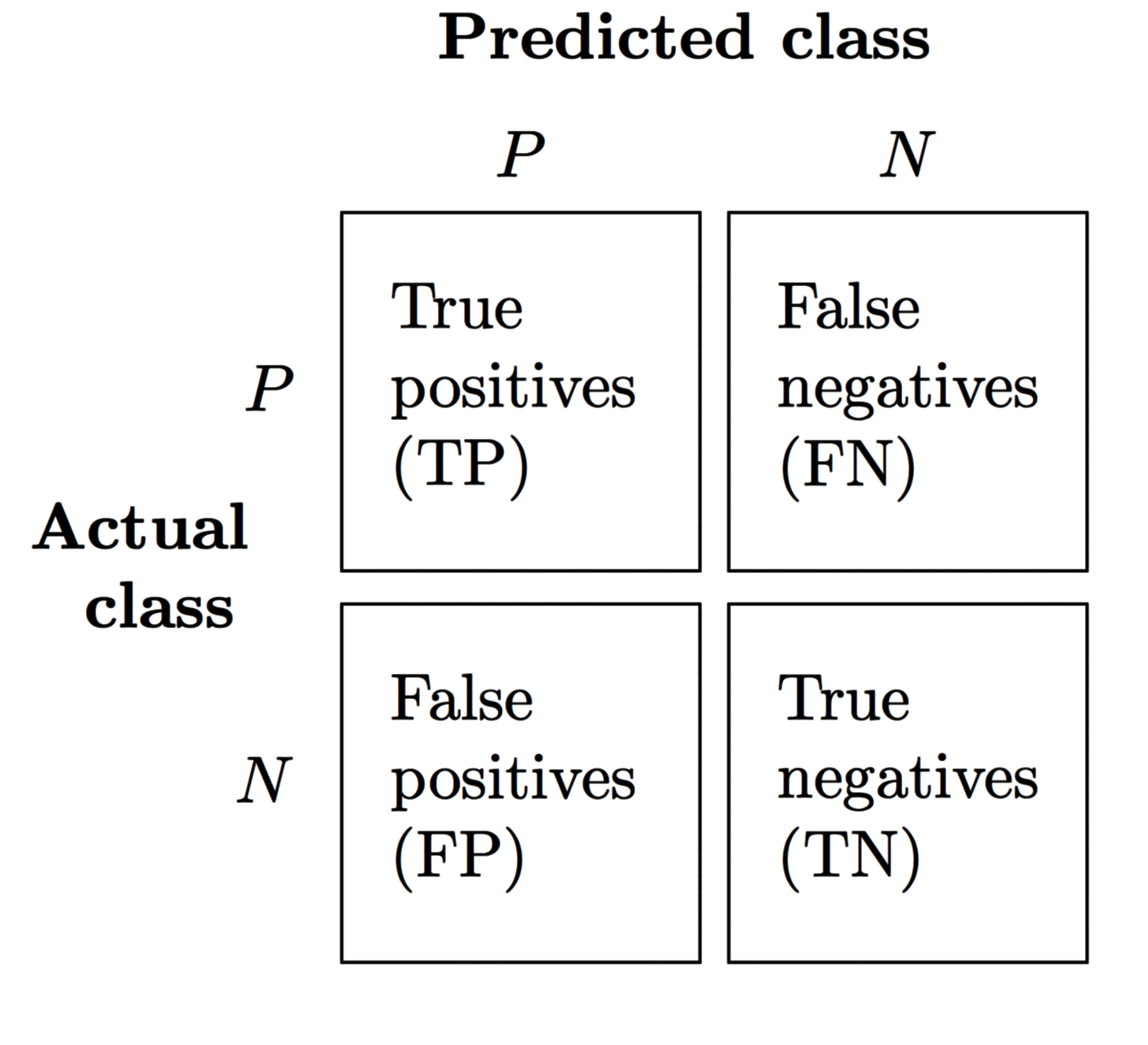
混淆矩阵的形式为 True/False + Positive/Negative (Positive/Negative 是对于预测的类标签而言)。
混淆矩阵的 scikit-learn 演示
以 wdbc 数据集为例进行说明。先进行导入及预处理:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header=None,
)
X = df.iloc[:, 2:]
y = df.iloc[:, 1]
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=1
)
pipe_svc = make_pipeline(StandardScaler(), SVC(random_state=1))
通过 sklearn.metrics.confusion_matrix 计算混淆矩阵:
from sklearn.metrics import confusion_matrix
pipe_svc.fit(X_train, y_train)
y_pred = pipe_svc.predict(X_test)
confmat = confusion_matrix(y_true=y_test, y_pred=y_pred)
print(confmat)
上面的函数打印出了 pipe_svc 在测试集上的混淆矩阵:
需要注意的是,scikit-learn 的混淆矩阵排列方式为 [[TN,FP],[FN,TP]]。
[[71 1]
[ 2 40]]
为了更直观地说明,通过 matplotlib 绘图如下:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(2.5, 2.5))
ax.matshow(confmat, cmap=plt.cm.Blues, alpha=0.3)
for i in range(confmat.shape[0]):
for j in range(confmat.shape[1]):
ax.text(x=j, y=i, s=confmat[i, j], va="center", ha="center")
plt.xlabel("predicted label")
plt.ylabel("true label")
plt.show()
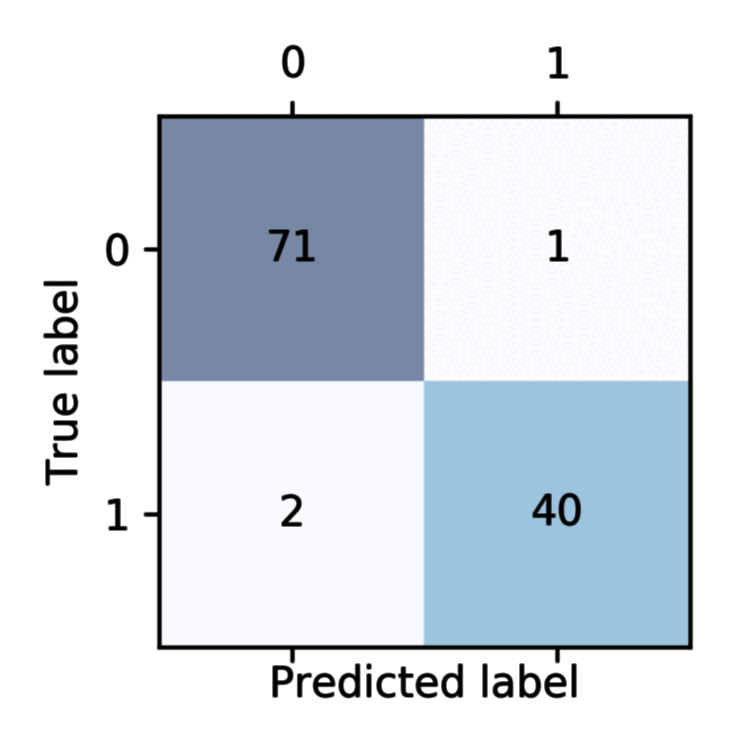
这个数据集的类标签为病情恶性或者良性,通过 LabelEncoder 进行分类标签编码,恶性为 1 (正),良性为 0 (负)。
- 左上:TN,预测为良性且预测正确的样本数。
- 右上:FP,预测为恶性且预测错误 (实际上为良性) 的样本数。
- 左下:FN,预测为良性且预测错误 (实际上为恶性) 的样本数。
- 右下:TP,预测为恶性且预测正确的样本数。
虽然大部分情况下比较关注分类正确 (TN + TP) 的表现。但是对于一些实际问题而言,FP 和 FN 是不一样的。以上述的 wdbc 数据而言,如果把良性病情预测恶性 (FP),患者很有可能再后续再进行复查;但是如果把恶性病情预测成良性 (FN),可能会让患者掉以轻心以拖延治疗,相比 FP 而言会带来更严重的后果。这也是需要制定不同评估指标的原因。
为了便于记忆,FP 也称 false alarm,可以理解为报警铃的误报;FN 也称 miss,应该报警但是实际没有报警。
评估指标介绍
下图来自 Wikipedia - Confusion matrix:
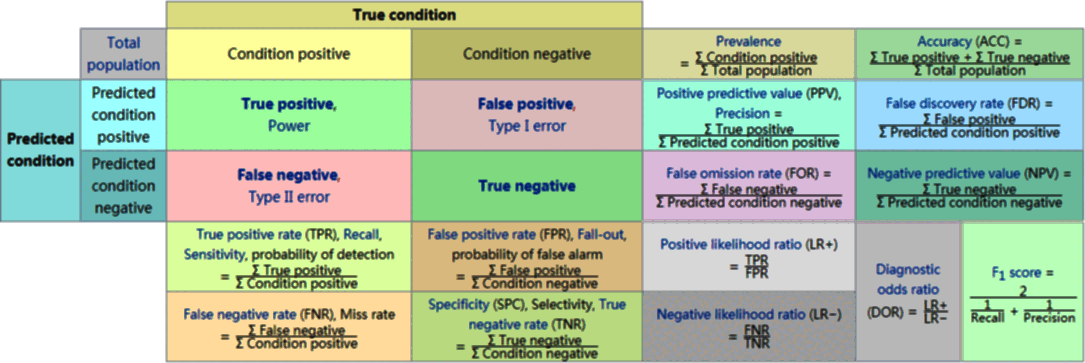
下面介绍其中一些重要的评估指标,其中 表示实际为正的样本数, 表示实际为负的样本数。
准确率
ACC (Accuracy) 代表准确率,ERR (Error) 代表错误率:
scikit-learn 实现如下:
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_true=y_test, y_pred=y_pred)
召回率
召回率 (Recall) 即 TPR (True Positive Rate),表示实际为正的样本中正确预测的概率,也称敏感度 (Sensitivity) 或命中率 (Hit Rate):
scikit-learn 实现如下:
from sklearn.metrics import recall_score
recall = recall_score(y_true=y_test, y_pred=y_pred)
精准率
精准率 (Precision) 即 PPV (Positive Predictive Value),表示预测为正的样本中正确预测的概率:
scikit-learn 实现如下:
from sklearn.metrics import precision_score
precision = precision_score(y_true=y_test, y_pred=y_pred)
F1 分数
F1 分数 (F1 Score) 是召回率和精准率的调和平均值:
scikit-learn 实现如下:
from sklearn.metrics import f1_score
f1 = f1_score(y_true=y_test, y_pred=y_pred)
马修斯相关系数
马修斯相关系数 (Matthews Correlation Coefficient,MCC) 对多个指标进行综合打分:
scikit-learn 实现如下:
from sklearn.metrics import matthews_corrcoef
mcc = matthews_corrcoef(y_true=y_test, y_pred=y_pred)
替换 scikit-learn 的评估指标
需要注意的是,scikit-learn 中大多数算法默认使用 accuracy_score 作为评估指标。另外,其中正类认为是的标签为 1 的类。
通过 sklearn.metrics.make_scorer 可以替换评估指标和正类的类标签:
from sklearn.metrics import make_scorer, f1_score
scorer = make_scorer(f1_score, pos_label=0)
gs = GridSearchCV(estimator=pipe_svc, param_grid=param_grid, scoring=scorer, cv=10)
gs = gs.fit(X_train, y_train)
print(gs.best_score_)
# Output: 0.986202145696
>>> print(gs.best_params_)
# Output: {'svc__C': 10.0, 'svc__gamma': 0.01, 'svc__kernel': 'rbf'}
有关评估指标的更多内容,请参见 Wikipedia - Confusion matrix 和 sklearn.metrics。