学习曲线和验证曲线
绘制模型的学习曲线 (Learning Curve) 和验证曲线 (Validation Curve) 是常用的调试手段,能够从中直观看到模型在测试集和验证集上的表现,以及判断是否有过拟合或欠拟合问题。
方差 - 偏差权衡
通过曲线可以容易看出模型是否存在高偏差或高偏差,以及判断否能够通过增加样本数目解决这些问题。
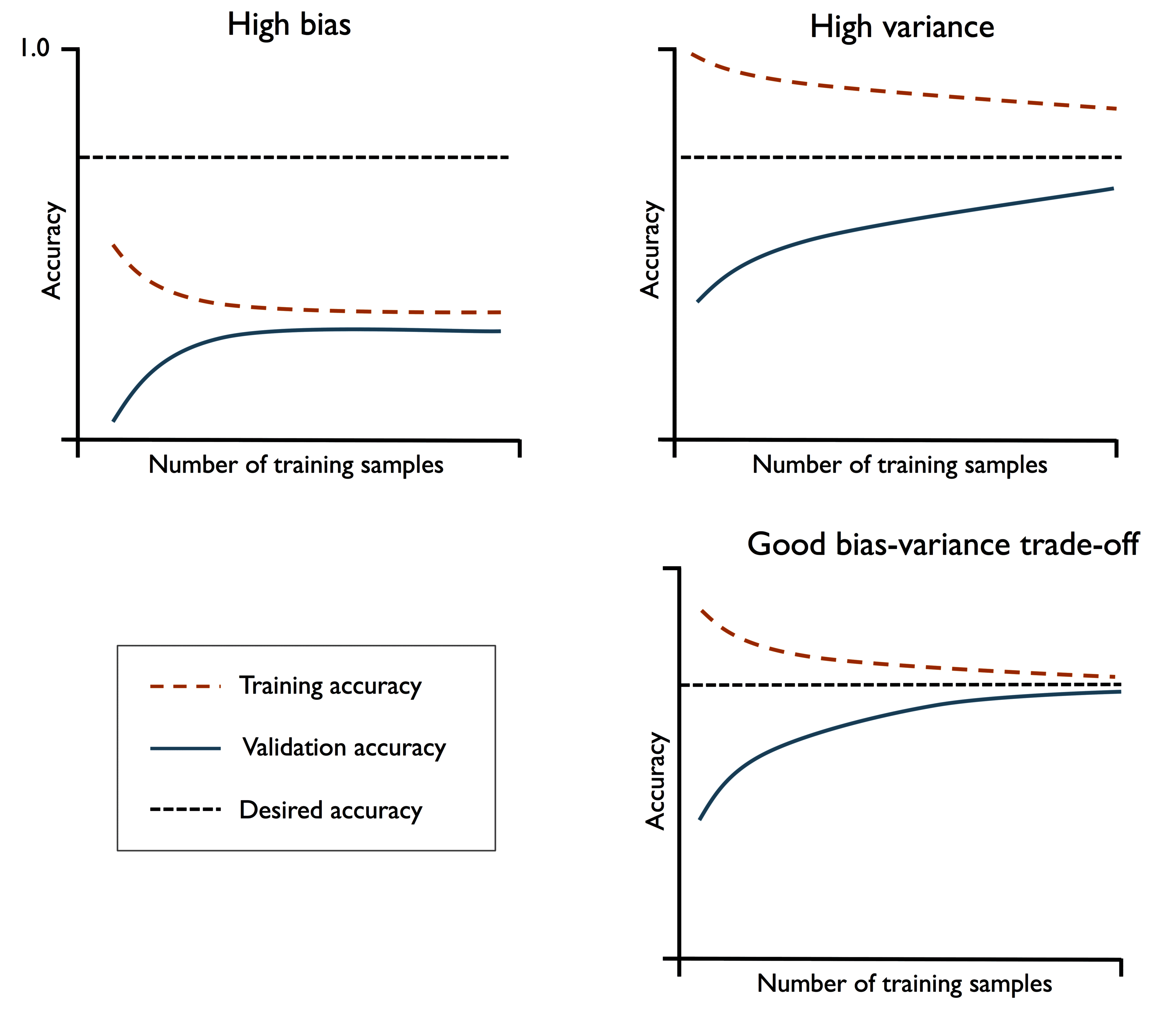
常见的学习曲线如下图所示:
- 左上子图:学习曲线和验证曲线都很差,高偏差、欠拟合。
- 右上子图:学习曲线很好但验证曲线很差,高方差、过拟合
- 右下子图:在拥有一定数量样本的情况下,具有良好的方差 - 偏差权衡 (bias-variance tradeoff) 和拟合程度。
学习曲线
绘制学习曲线时,自变量为样本数,因变量为评价指标。
读取 wdbc 数据集,并将其分为 80% 的训练集和 20% 的测试集:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
df = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header=None,
)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, stratify=y, random_state=1
)
使用 sklearn.model_selection.learning_curve 生成学习曲线的值,然后通过 pyplot 绘制模型对于训练集和验证集的准确率:
pipe_lr:scikit-learn 管道对象train_sizes:测试集为数据集X_train的比例 (这里为 10%、20%、…、100%)cv:分层交叉验证的折叠数 Kn_jobs:使用的 CPU 核心数train_scores和test_scores:共有len(train_sizes)行,每行有cv个交叉验证的分数,因此均值标准差都是按行计算axis=1plt.fill_between:通过标准差绘制数据的离散程度
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
pipe_lr = make_pipeline(StandardScaler(), LogisticRegression(random_state=1))
train_sizes, train_scores, test_scores = learning_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=10,
n_jobs=1,
)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(
train_sizes,
train_mean,
color="blue",
marker="o",
markersize=5,
label="training accuracy",
)
plt.fill_between(
train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15,
color="blue",
)
plt.plot(
train_sizes,
test_mean,
color="green",
linestyle="--",
marker="s",
markersize=5,
label="validation accuracy",
)
plt.fill_between(
train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color="green"
)
plt.grid()
plt.xlabel("Number of training samples")
plt.ylabel("Accuracy")
plt.legend(loc="lower right")
plt.ylim([0.8, 1.03])
plt.show()
得到模型的准确率随样本数变化的曲线:
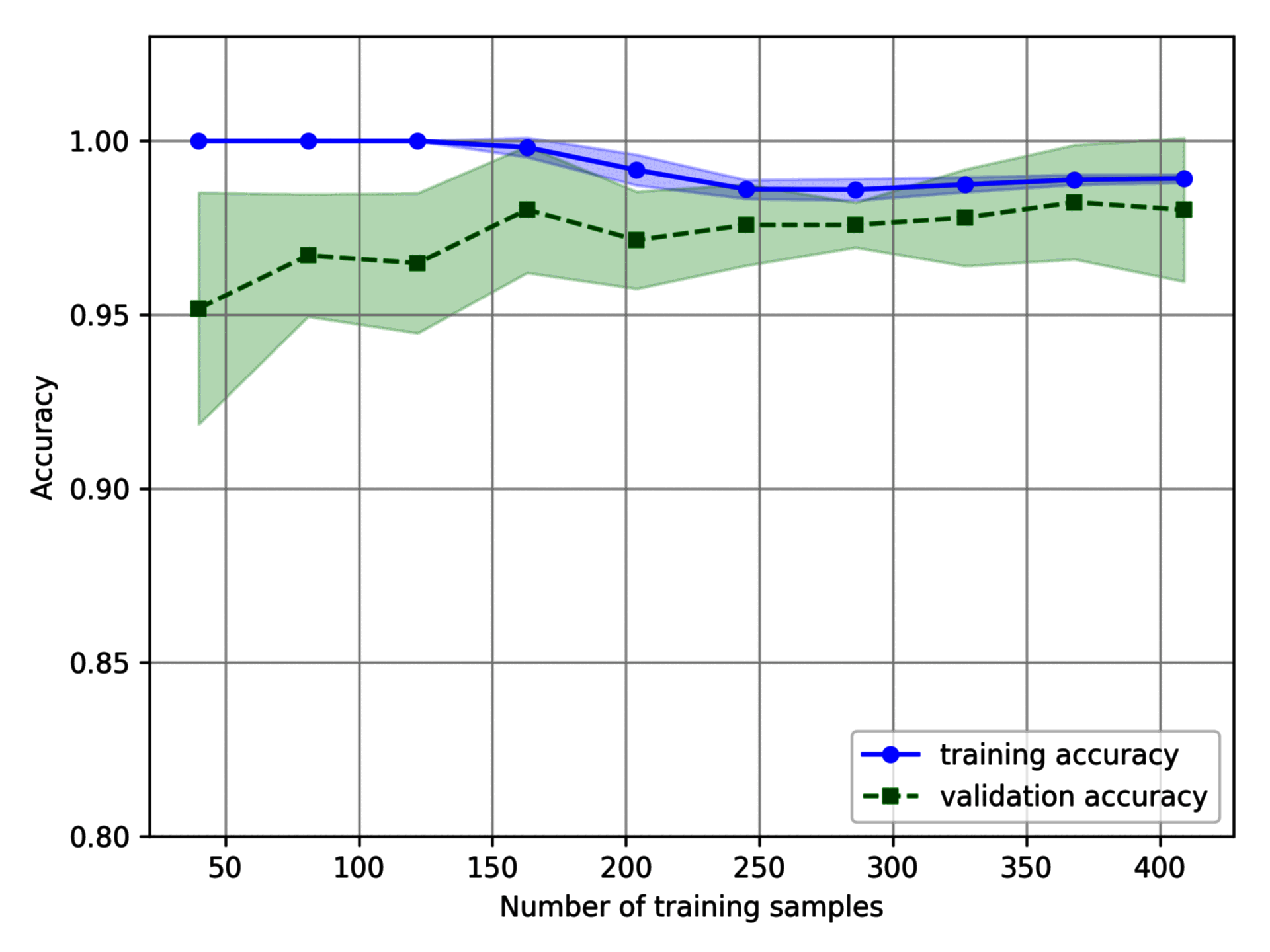
若训练集的样本数小于 250,训练集的准确率很高,但是测试集的准确率相对较低,模型存在过拟合问题。若训练集的样本数大于 250,则模型在训练集和验证集上的表现都非常好。
验证曲线
和学习曲线不同,验证曲线的因变量往往是模型的参数值,如逻辑回归中的参数 C。
使用 sklearn.model_selection.validation_curve 生成学习曲线的值,然后通过 pyplot 绘制模型对于训练集和验证集的准确率:
pipe_lr:scikit-learn 管道对象logisticregression__C:逻辑回归的超参数C,正则化系数的倒数param_range:超参数的取值范围
from sklearn.model_selection import validation_curve
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
train_scores, test_scores = validation_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
param_name="logisticregression__C",
param_range=param_range,
cv=10,
)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(
param_range,
train_mean,
color="blue",
marker="o",
markersize=5,
label="training accuracy",
)
plt.fill_between(
param_range,
train_mean + train_std,
train_mean - train_std,
alpha=0.15,
color="blue",
)
plt.plot(
param_range,
test_mean,
color="green",
linestyle="--",
marker="s",
markersize=5,
label="validation accuracy",
)
plt.fill_between(
param_range, test_mean + test_std, test_mean - test_std, alpha=0.15, color="green"
)
plt.grid()
plt.xscale("log")
plt.legend(loc="lower right")
plt.xlabel("Parameter C")
plt.ylabel("Accuracy")
plt.ylim([0.8, 1.03])
plt.show()
得到模型的准确率随逻辑回归参数 C 变化的曲线:
在正则化强度较大 (C 小于 0.01) 时,模型有一定程度的欠拟合 (高偏差),但在正则化强度较小 (C 大于 10) 时,模型又会出现过拟合 (高方差)。超参数 C 的取值在 0.01 和 0.1 之间时,模型性能最优。