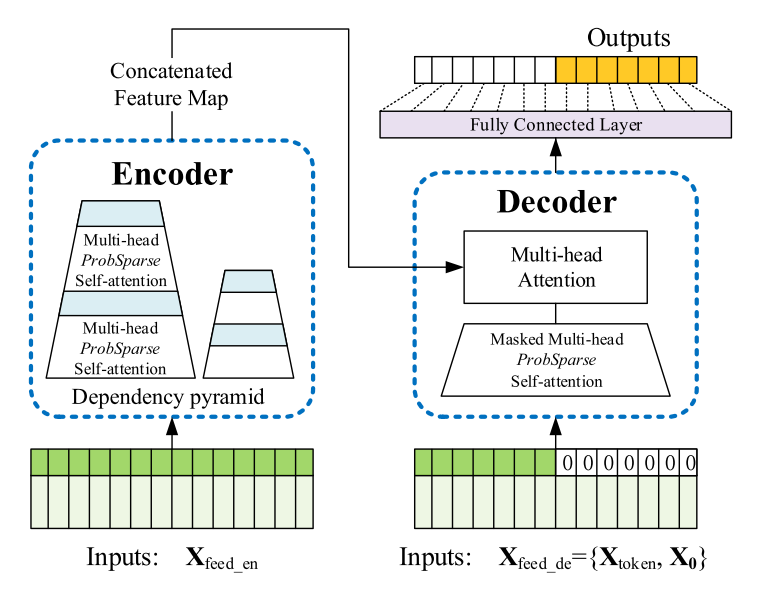
Transformer 的变种
Informer
Informer 在论文 Informer:Beyond Efficient Transformer for Long Sequence Time-Series Forecasting 中提出,对经典的 Transformer 提出了一些改进,用于长时间序列预测 (Long sequence time-series forecasting,LSTF) 任务,包括:
- ProbSparse 自注意力机制,其时间复杂度和内存使用量达到 ,并且在序列的依赖性对齐方面具有相近的性能;
- 自注意力蒸馏通过将级联层输入减半来突出主导注意力,并有效处理极长的输入序列;
- 在生成式的解码器中,通过一次前向操作而不是一步一步的方式来预测长时间序列,大大提高了长序列预测的推理速度。
Informer 源码开源在 GitHub - Informer2020。
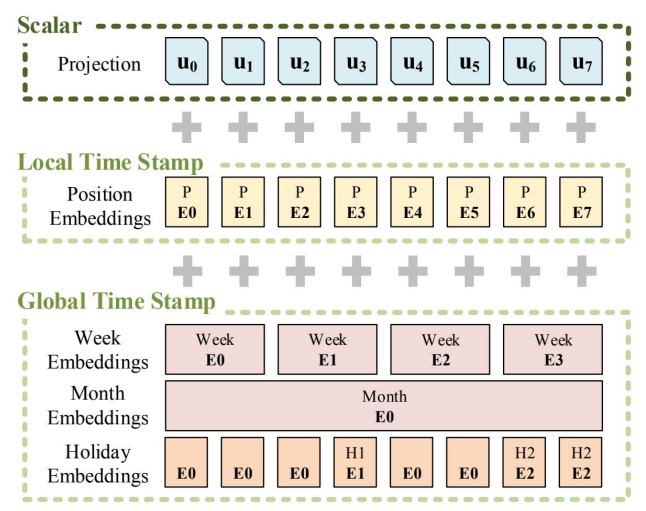
Informer 的 Embedding 层
除了输入 embedding 和位置编码外,informer 还引入了时间维度的 embedding:
ProbSparse 自注意力机制
在注意力机制矩阵中,不是每一列都是有 attention 作用的,因此选择 矩阵中贡献率最高的 top- 行,其中 取值 , 是常数。
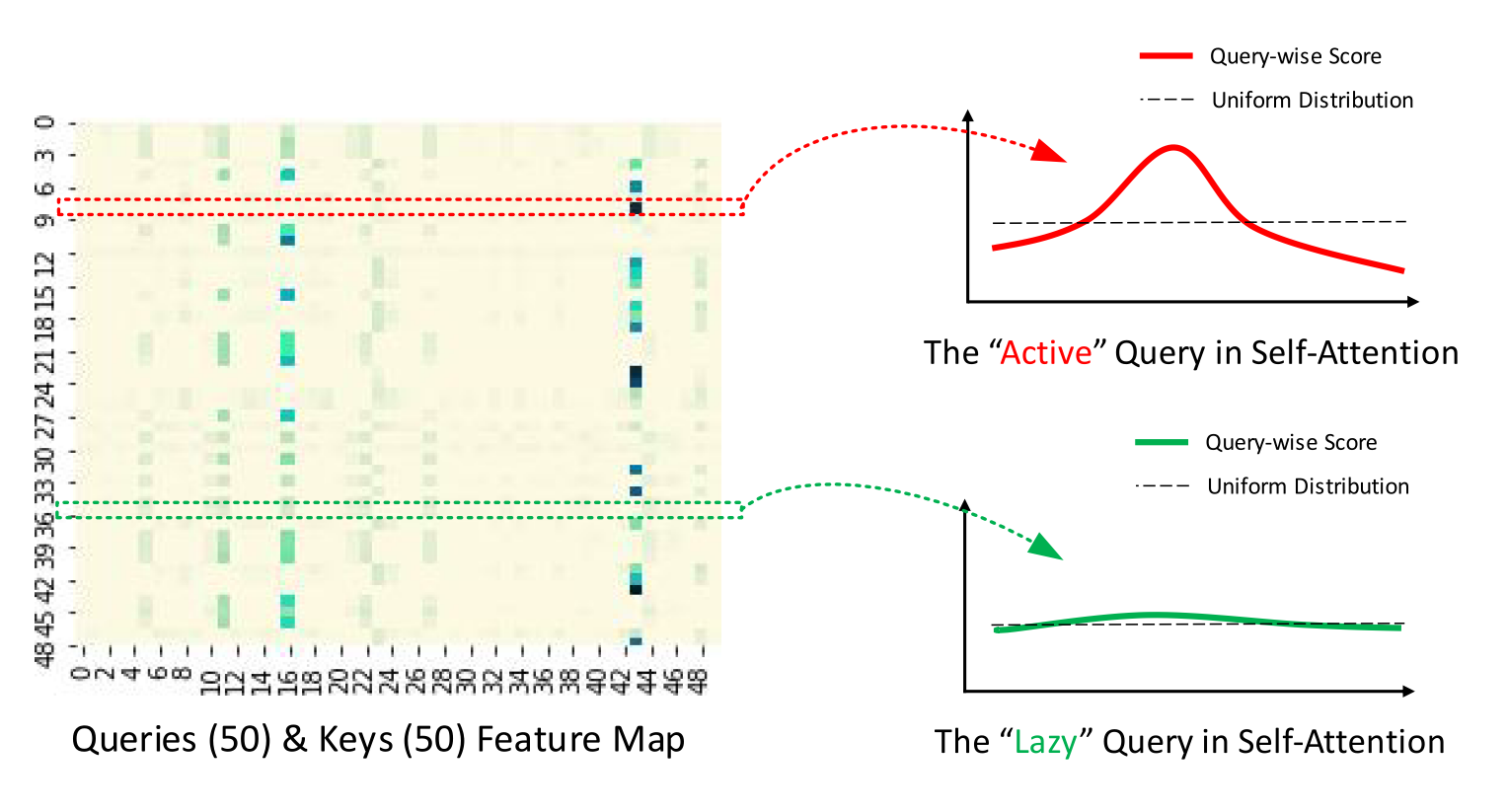
ProbSparse 通过计算 KL 散度 (Kullback-Leibler divergence) 来得到不同行注意力的贡献率。KL 散度在统计模型中可以反映信息增益,当两个分布差异较大的时候,KL 散度结果数值会越高。
通过计算每一行实际的 attention 和均匀分布 attention 的 KL 散度,可以近似衡量这一行对注意力的贡献。
但是这样计算后,内存使用并没有减少。所以作者又提出了随机选择 行。
经过以上处理,模型的注意力矩阵内存和时间复杂度都从 减少到 。
这里需要注意的是,原始论文中计算 后,在经典的 Transformer 的基础上,把 Informer 中没有参与计算的位置,使用平均权重填充。因此第一层注意力层的输出的形状和经典的 Transformer 保持一致。
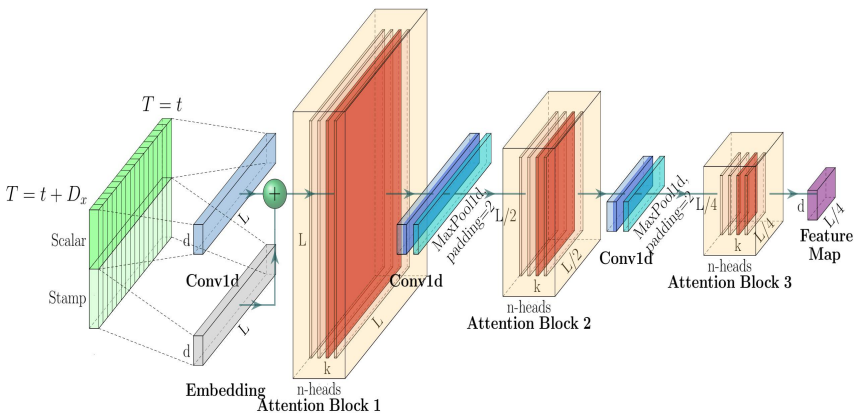
卷积池化减半
原始的注意力层的输出结果数据尺寸不会变化,但是 Informer 中会进行池化减半操作。减小了计算量和训练时间。
这里的减半操作是使用卷积神经网络中步长为 2 的最大池化 (MaxPooling)。
单次解码器设计
经典的 Transformer 用于 NLP,很多时候每个输出结果和之前的单词具有语义上的紧密联系,因此按照一步一步的输出比较适合。
在 Informer 中,由于预测未来某一些时刻的指标,这些指标之前没有类似于 NLP 中前后强关联的语义关系,因此可以采用单次输出所需要的序列,极大的提高了推理速度。