注意力机制
什么是注意力机制
人类的图像注意力
简单来说,注意力就是我们关注的重点。

以上图的柴犬为例,人类的视觉注意力可以聚焦于图像的某个 (或者某些) 区域,同时忽略其余的区域。
人类的文本注意力
类似的,在文本中也有注意力机制,在阅读某一个词的时候,我们会去同时关注其他某些相关的词。

Transformer 的注意力机制
Transformer 的注意力机制是 Transformer 架构的核心。
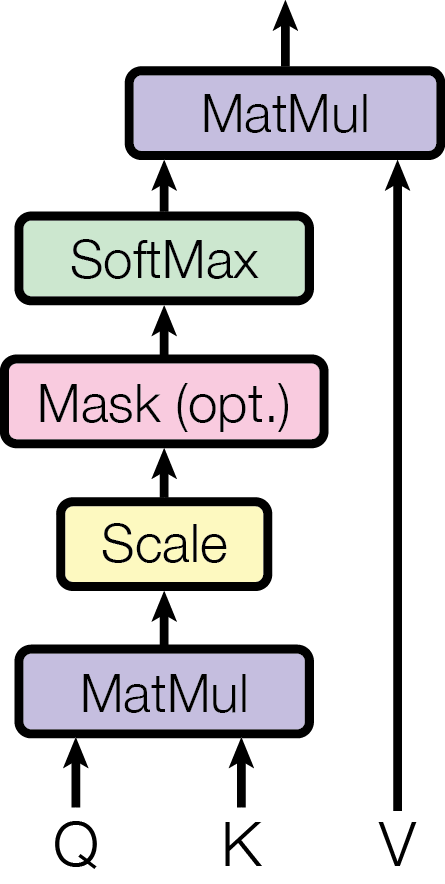
理解注意力机制的 / /
毫不夸张的说,、、 是天才设计。也是大模型的基石。如何理解 、、?
以爬山为例,假设您想要估算当前的海拔高度,但没有直接获得这个信息。相反,您使用望远镜观察到周围有若干个碑石:
- 离你最近的上方碑石的信息:海拔 2000 米;离你较远
- 离你最近的下方碑石的信息:海拔 1800 米;离你较近
我们预测当前的海拔高度为: (米)。
现在,让我们将这个过程解释为注意力机制的步骤:
- :当前状态,作为查询
- :观测到的碑石状态 (键值)
- :碑石存储的数值信息
是点积。SoftMax 让其概率为之和为 1。
为了解决维度过高带来的影响,Transformer 设计的时候,使用了缩放的点积。
理解
我们看一下 和 :
其中 和 是多维向量,维度为嵌入向量的维度 。
的结果为:
上面的 是向量的点积结果,用于表征查询 和键值 之间的匹配程度。
自注意力机制
注意力机制为查询和目标之间的注意力,比如在翻译任务中,源语言和翻译的目标语言是不同的。
在查询为目标本身的时候,为注意力的一种特殊形式:自注意力。
自注意力可以分为两种情况:
- 前向关注 (关注这个 token,和之前的其余 tokens)
- 双向关注 (关注这个 token,和之前以及之后的 tokens)
自注意力中的 mask
在自注意力相关性中,mask 代表关注的程度。由于矩阵天然具有前后双向关注的特性,如果我们只需要关注于之前的 tokens,则需要添加屏蔽之后 attention 的 mask。
![]()
通常来说,前向关注的注意力机制也称为因果注意力 (casual attention)。
在因果注意力中,为了保持自回归性质,注意力机制会限制每个位置只能注意到其之前的位置,而不是整个输入序列。
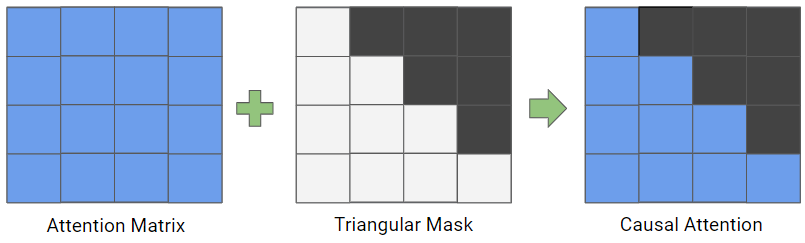
在代码实现中,可以在计算 或者计算 后,将右上部分 (不包含对角线) 设置成负无穷大或者一个非常大的负值 (如 1e-9),这样在经过 SoftMax 之后,对应位置的 attention score 接近为 0。