线性 SVM
支持向量机 (Support Vector Machine,SVM) 是一种监督式学习方法,其学习策略为最大化样本与超平面 (即决策边界) 之间的间隔。本文介绍线性 SVM 的原理及实现。
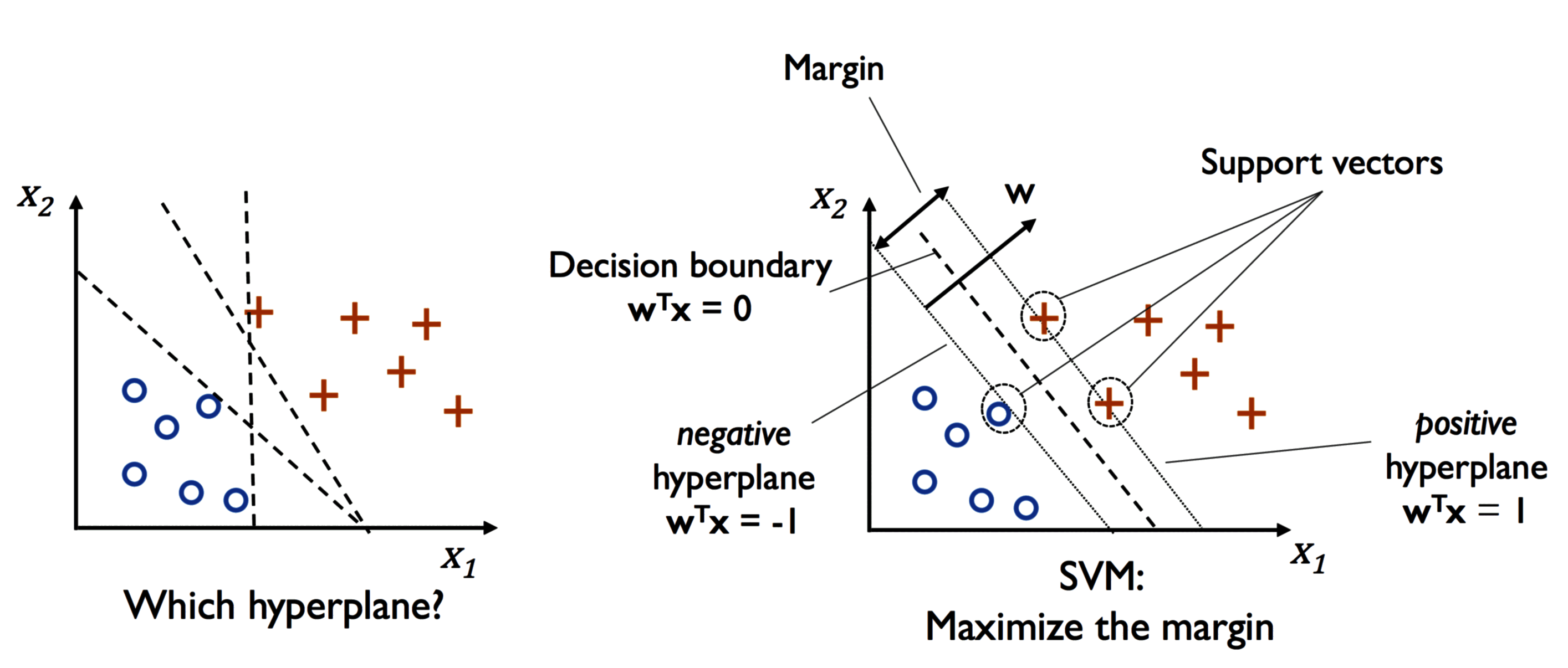
间隔被定义为分离超平面与最靠近这个超平面的训练样本之间的距离。
这些影响边界的特殊样本称为支持向量,也是算法称为支持向量机的原因。
硬间隔 SVM
为了得到边缘最大化,与决策边界平行的正负超平面可以用数学表示如下:
相减得到:
对上式中的 进行向量归一化:
这两个超平面之间的距离是 ,要使两平面间的距离最大,我们需要最小化 。
同时为了使得样本数据点都在超平面的间隔区以外,我们需要保证对于所有的 满足以下条件之一:
上式等同于:
硬间隔 SVM 的目标是在上式约束条件下,最小化 ;在实际中,一般是最小化 。
软间隔 SVM
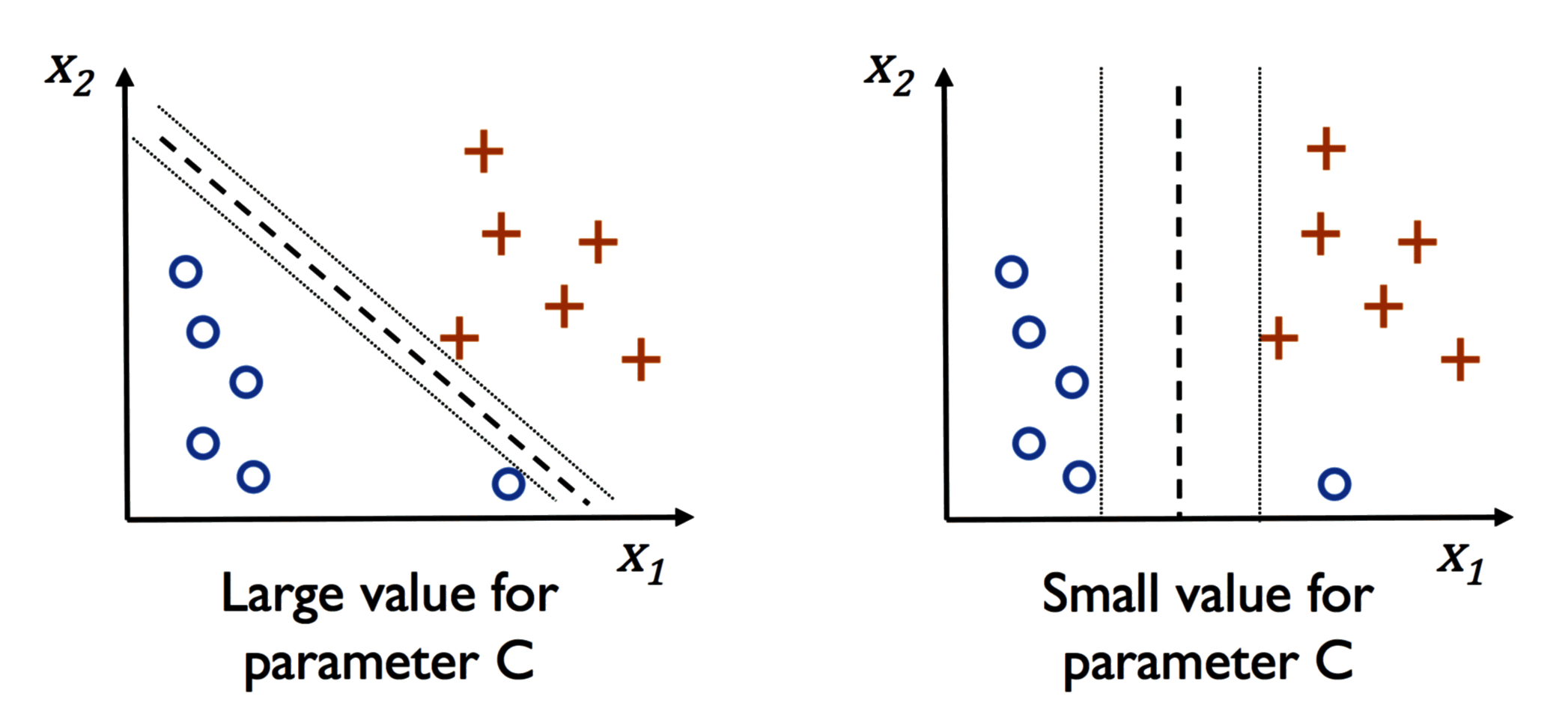
SVM 在软间隔分类器中引入了松弛变量 ,它允许分类器对一些样本犯错,允许一些样本不满足硬间隔约束条件。
这样做可以避免 SVM 分类器过拟合,于是也就避免了模型过于复杂,降低了模型对噪声点的敏感性,提升了模型的泛化性能。
带松弛变量的分类器约束条件如下:
软间隔 SVM 的目标是最小化 。
参数 可以平衡偏差和方差。 越大,算法分类越严格,方差越高,过大的 可能会引起过拟合;反之同理。
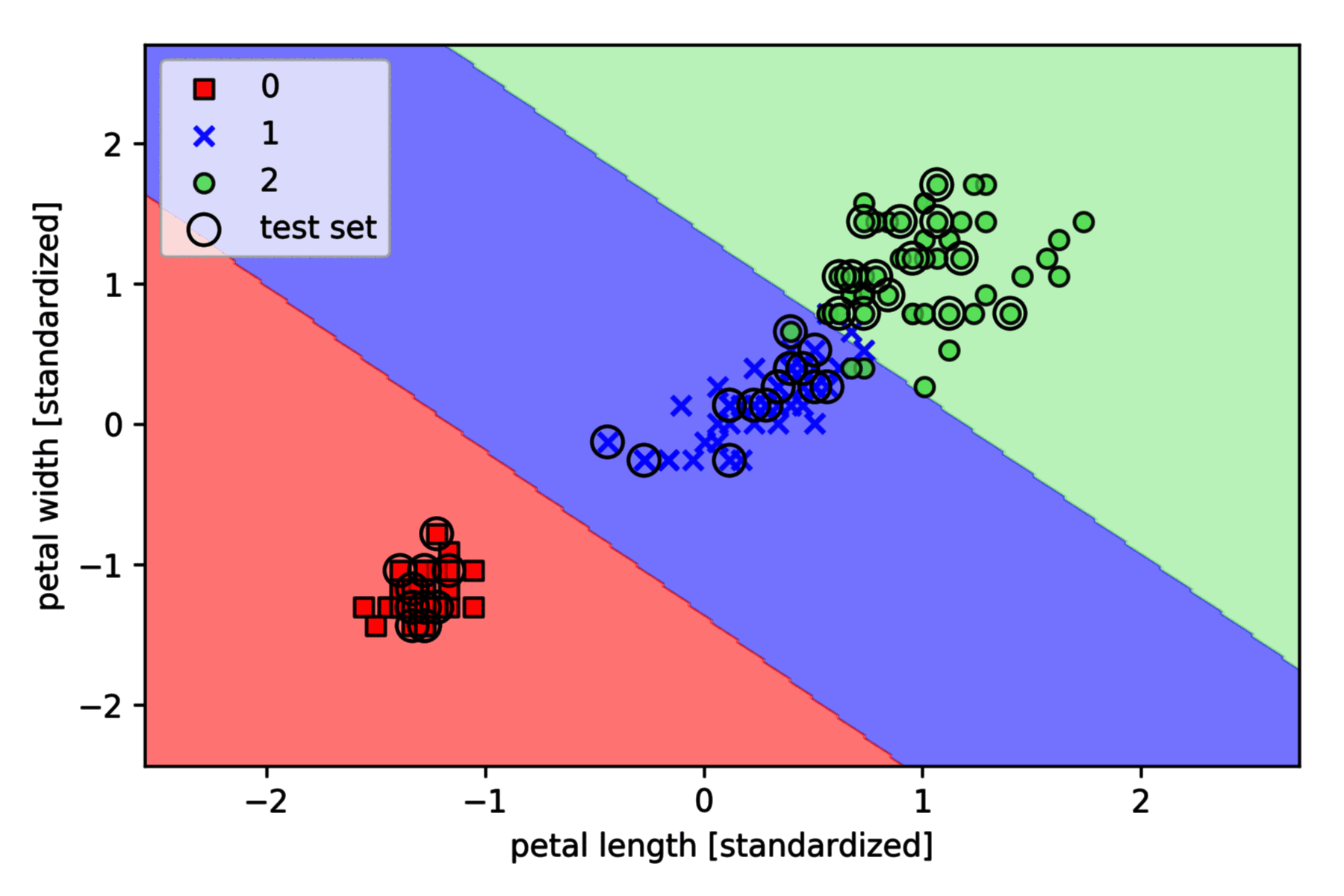
以 Iris 数据集为例,基于 Scikit-learn 的实现如下 (其中决策边界绘制函数 plot_decision_regions 请参见之前的文章):
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=1, stratify=y
)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
svm = SVC(kernel="linear", C=1.0, random_state=1)
svm.fit(X_train_std, y_train)
plot_decision_regions(
X_combined_std, y_combined, classifier=svm, test_idx=range(105, 150)
)
plt.xlabel("petal length [standardized]")
plt.ylabel("petal width [standardized]")
plt.legend(loc="upper left")
plt.show()