使用集合的投票分类方法
集合 (Ensemble) 方法的目标是将不同的分类器组合到一起,相比每个单独的分类器具有更好的泛化性能。
算法描述
如果 10 位专家的预测分别如下,集合方法可以将其预测结果结合起来,从而得出比每位专家的预测更精确和更稳健的预测:
- 一致 (Unanimity):预测情况一致
- 绝对多数投票 (Majority Voting):预测情况不同,取高于 50% 的预测结果,适用于二元分类
- 相对多数投票 (Plurality Voting):预测情况不同,取其中相对最高的预测结果,适用于多元分类
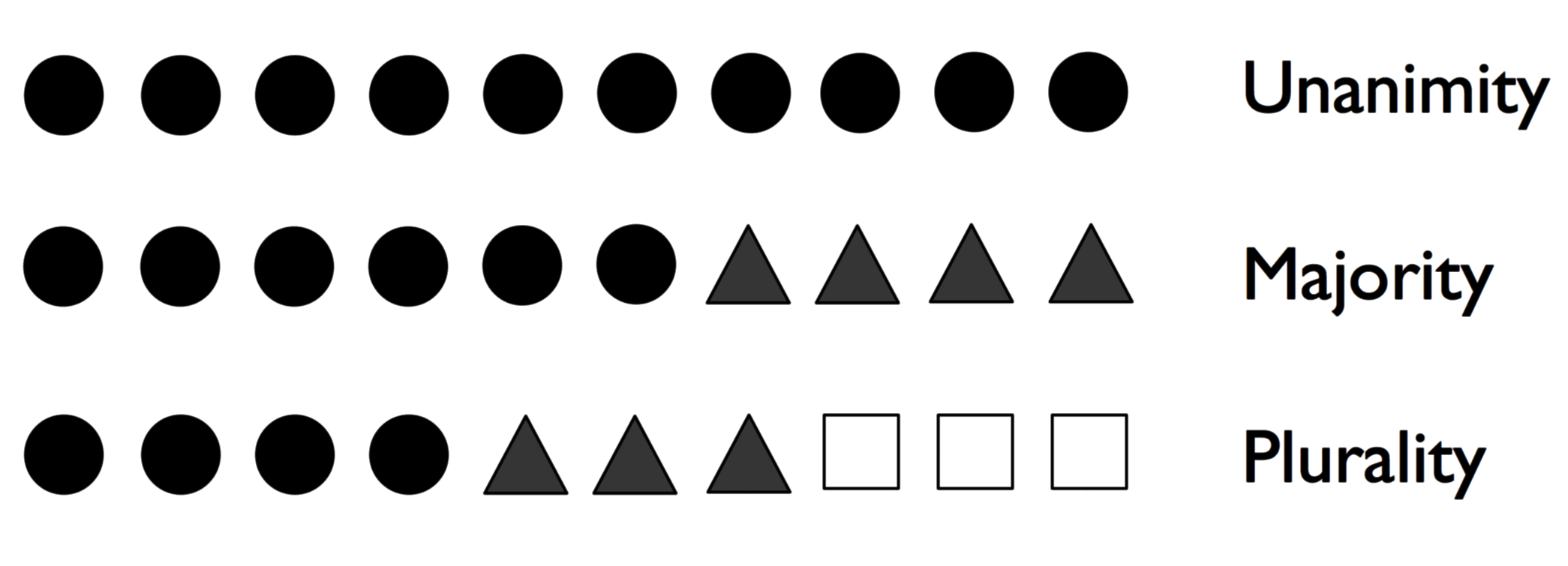
投票算法用于分类器时,可以取 m 个不同的分类器,然后使用不同的分类算法 (决策树、SVM、逻辑回归等) 构建集合;也可以使用相同的分类算法对不同的测试集进行评估。
以下为使用多数投票的集合方法实例,其中有 m 个分类器 以及其评估结果:
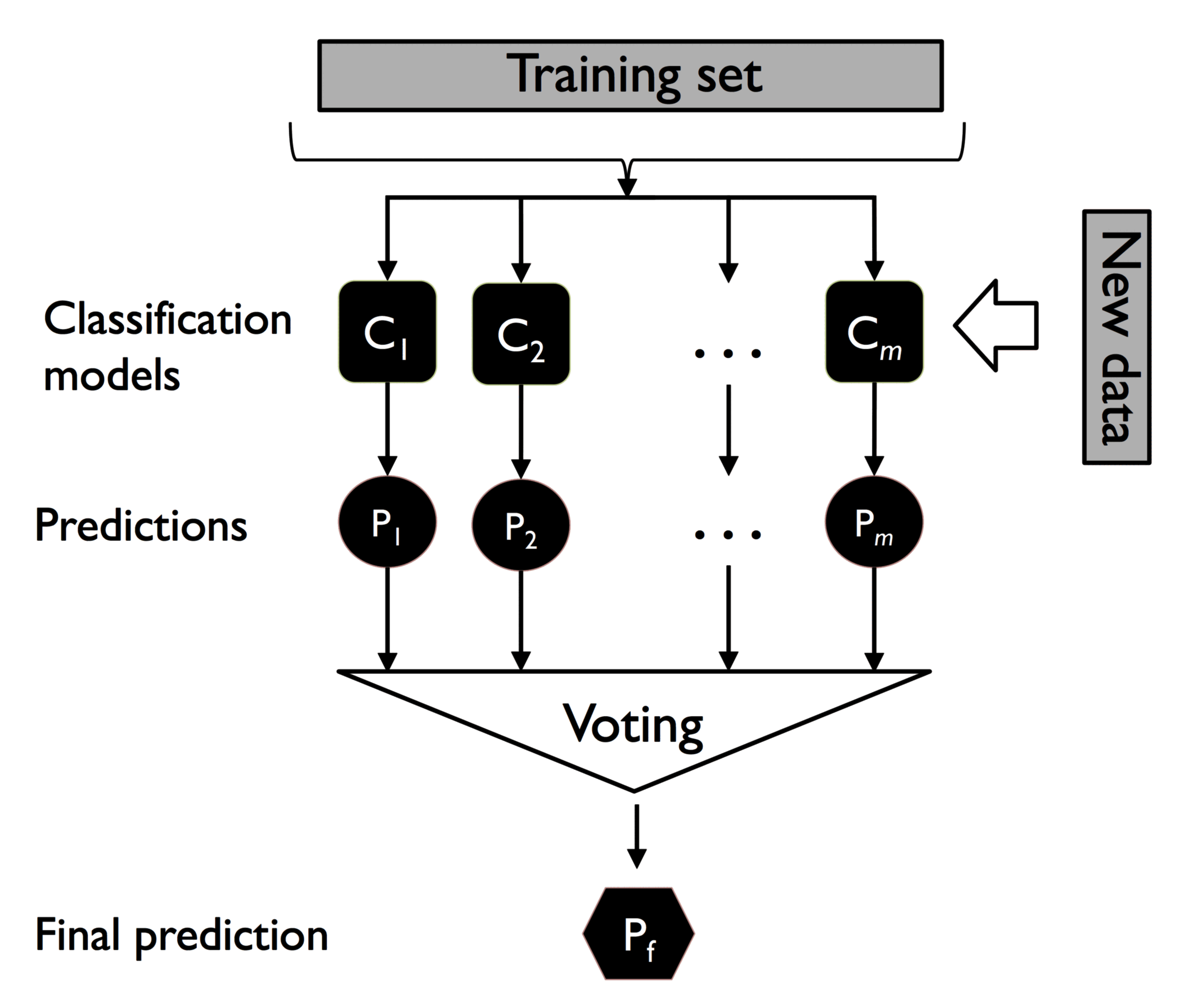
记 为输入, 为预测的众数:
在统计学中,使用 代表众数,即出现次数最多的元素。
算法思想
接下来阐述为什么集合在绝大多数情况下能够比单个分类器具有更好的表现。
以二元分类为例,假设单个分类器的错误率 \varepsilon=0.25,使用 11 个分类器 (假设其互不相关、且每个分类器的错误率相同) 的集合错误率显著降低:
其中 为二项式系数 。
上述的数学表达式在 python 中实现如下:
from scipy.misc import comb
import math
def ensemble_error(n_classifier, error):
k_start = int(math.ceil(n_classifier / 2))
probs = [
comb(n_classifier, k) * error**k * (1 - error) ** (n_classifier - k)
for k in range(k_start, n_classifier + 1)
]
return sum(probs)
print(ensemble_error(11, 0.25))
# Output: 0.034327507019042969
集合错误率和单个分类器错误率之前的关系绘图如下:
import numpy as np
import matplotlib.pyplot as plt
error_range = np.arange(0.0, 1.01, 0.01)
ens_errors = [ensemble_error(n_classifier=11, error=err) for err in error_range]
plt.plot(error_range, ens_errors, label="Ensemble Error", linewidth=2)
plt.plot(error_range, error_range, linestyle="--", label="Base Error", linewidth=2)
plt.xlabel("Base error")
plt.ylabel("Base/Ensemble error")
plt.legend(loc="upper left")
plt.show()
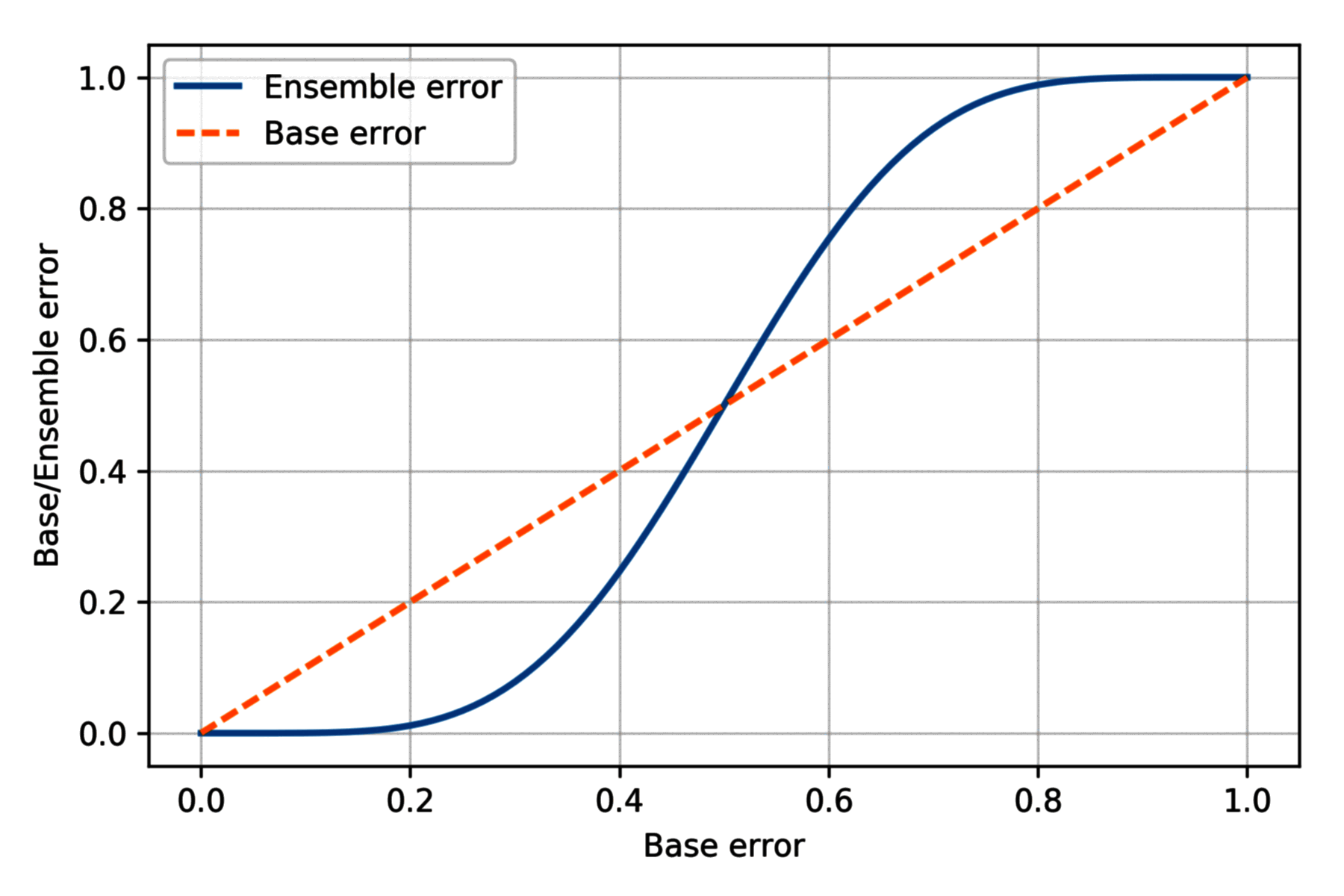
可以看的,只要单个分类器错误率小于 0.5 (二元分类可以轻易达到这个水平),那么使用集合能够模型提高模型的预测能力。
加权相对多数分类器
加权相对多数分类器的结果如下,其中 代表第 个分类器, 代表类标签:
为进行说明,假设有二元分类 (类标签 为 0 或 1),使用三个分类器的集合进行加权评估,每个分类器对于给定输入 的概率和权重如下:
- 第一个分类器预测为 0 和 1 和概率分别为 ,权重为 0.2。
- 第二个分类器预测为 0 和 1 和概率分别为 ,权重为 0.2。
- 第三个分类器预测为 0 和 1 和概率分别为 ,权重为 0.6。
预测为类 0 和类 1 的概率分别为:
最终的预测分类为 0:
ex = np.array([[0.9, 0.1], [0.8, 0.2], [0.4, 0.6]])
p = np.average(ex, axis=0, weights=[0.2, 0.2, 0.6])
print(p)
# Output: array([ 0.58, 0.42])
print(np.argmax(p))
# Output: 0
scikit-learn 中实现了投票分类,请参见 sklearn.ensemble.VotingClassifier。