入门:基于 Iris 数据集
机器学习主要包括预处理、训练、评估和预测阶段。本文演示了如何使用 scikit-learn 进行分类。
预处理
原始数据很少呈现为学习算法的最佳性能所需的形式和形状。因此,数据的预处理是任何机器学习应用程序中最关键的步骤之一。以鸢尾花数据集为例,我们可以将原始数据看作一系列花图,从中我们可以提取有意义的特征,如花的颜色,花萼和花瓣的长度和宽度。
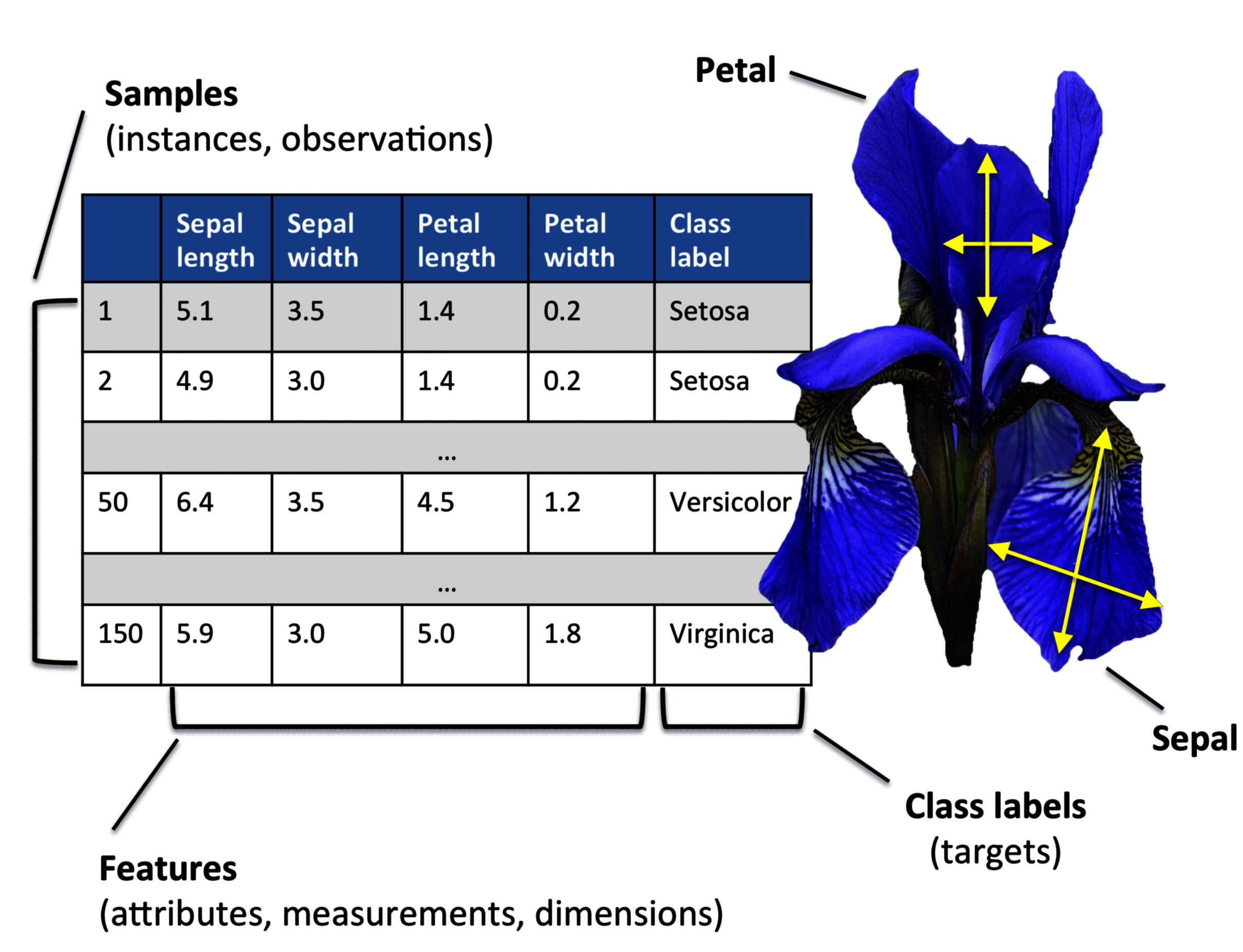
许多机器学习算法还要求能够将所有特征在同一数量级,这通常通过归一化或者正态分布等特征变换方法来实现。部分特征可能是高度相关的,特征可能存在冗余。在这种情况下,降维可以减少所需的存储空间,并且算法可以学习得更快。
为了确定机器学习算法是否不仅在训练集上表现良好的同时,能很好地预测到新的数据,我们将数据集随机分为相互独立的训练集和测试集。训练集用于训练和优化我们的机器学习模型,测试集用于最终评估最终模型。
在开始加载数据之前,按照常用约定导入这些库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
加载数据
您可以在此处下载 iris.csv。
names = ["sepal-length", "sepal-width", "petal-length", "petal-width", "class"]
dataset = read_csv("iris.csv", names=names)
探索性数据分析
打印 dataset 的形状:
print(dataset.shape)
# (150, 5)
打印 dataset 的前几行 (head() 默认打印 5 行):
print(dataset.head())
# sepal-length sepal-width petal-length petal-width class
# 0 5.1 3.5 1.4 0.2 Iris-setosa
# 1 4.9 3.0 1.4 0.2 Iris-setosa
# 3 4.6 3.1 1.5 0.2 Iris-setosa
# 2 4.7 3.2 1.3 0.2 Iris-setosa
# 4 5.0 3.6 1.4 0.2 Iris-setosa
打印 dataset 的 class 和每个 class 的数量:
print(dataset.groupby("class").size())
# class
# Iris-setosa 50
# Iris-versicolor 50
# Iris-virginica 50
# dtype: int64
打印 dataset 的统计数据:
print(dataset.describe())
# sepal-length sepal-width petal-length petal-width
# count 150.000000 150.000000 150.000000 150.000000
# mean 5.843333 3.054000 3.758667 1.198667
# std 0.828066 0.433594 1.764420 0.763161
# min 4.300000 2.000000 1.000000 0.100000
# 25% 5.100000 2.800000 1.600000 0.300000
# 50% 5.800000 3.000000 4.350000 1.300000
# 75% 6.400000 3.300000 5.100000 1.800000
# max 7.900000 4.400000 6.900000 2.500000
测试集训练集划分
有些文章将 train-test-split 作为数据预处理过程,有些文章认为这是一个训练过程。
在我看来,它是数据预处理和训练之间的桥梁。
将原始数据随机分成 80% 的训练集和 20% 的测试集:
from sklearn.model_selection import train_test_split
array = dataset.values
X = array[:, 0:4]
y = array[:, 4]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, shuffle=True, random_state=1
)
random_state 是用于分割的随机种子。设置后,将在不同的计算机上生成相同的训练数据集和测试数据集,以便重现结果。
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# (120, 4) (30, 4) (120,) (30,)
训练
目前已有许多不同的机器学习算法,用于解决不同的问题任务。每个分类算法都有其固有的偏差,在实践中,比较几个不同的算法然后从中选出最优算法,对于训练和选择最佳性能模型至关重要。一个常用的算法度量指标是分类准确率,即正确分类数据的比重。
另外,我们可以使用不同的交叉验证技术,其中将训练数据集进一步分为训练和验证子集,以估计模型的泛化性能。
最后,算法的默认参数对于实际问题往往不会具有最佳表现。因此,我们可以使用超参数优化技术,通过调节算法参数,我们可以提高算法的性能。
在训练之前,我们需要知道我们面临什么样的问题:这是一个多类分类监督问题。我们可以使用 DecisionTreeClassifier 分类器。
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, Y_train)
评估和预测
在选择了模型并使用训练集进行训练之后,我们可以使用测试集来来估计泛化误差。
如果我们对其性能感到满意,可以使用这个模型来预测新的未来数据。
需要注意的是,训练的参数 (如特征缩放和降维) 仅从训练数据集中获得,在测试数据上测量的性能可能是过拟合的。
进行评估:
print(f"Score of tree_model: {tree_model.score(X_validation, Y_validation)}")
# Score of tree_model: 0.9666666666666667
对新的未知数据进行分类:
print(
f"Prediction of [6.0, 3.1, 5.1, 1.9]: {tree_model.predict([[6.0, 3.1, 5.1, 1.9]])[0]}"
)
# Prediction of [6.0, 3.1, 5.1, 1.9]: Iris-virginica