机器学习三大类型
本文介绍机器学习的三大类型:监督式学习、非监督式学习和强化学习。
机器学习在近 30 多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA 序列测序、语音和手写识别、战略游戏和机器人等领域。
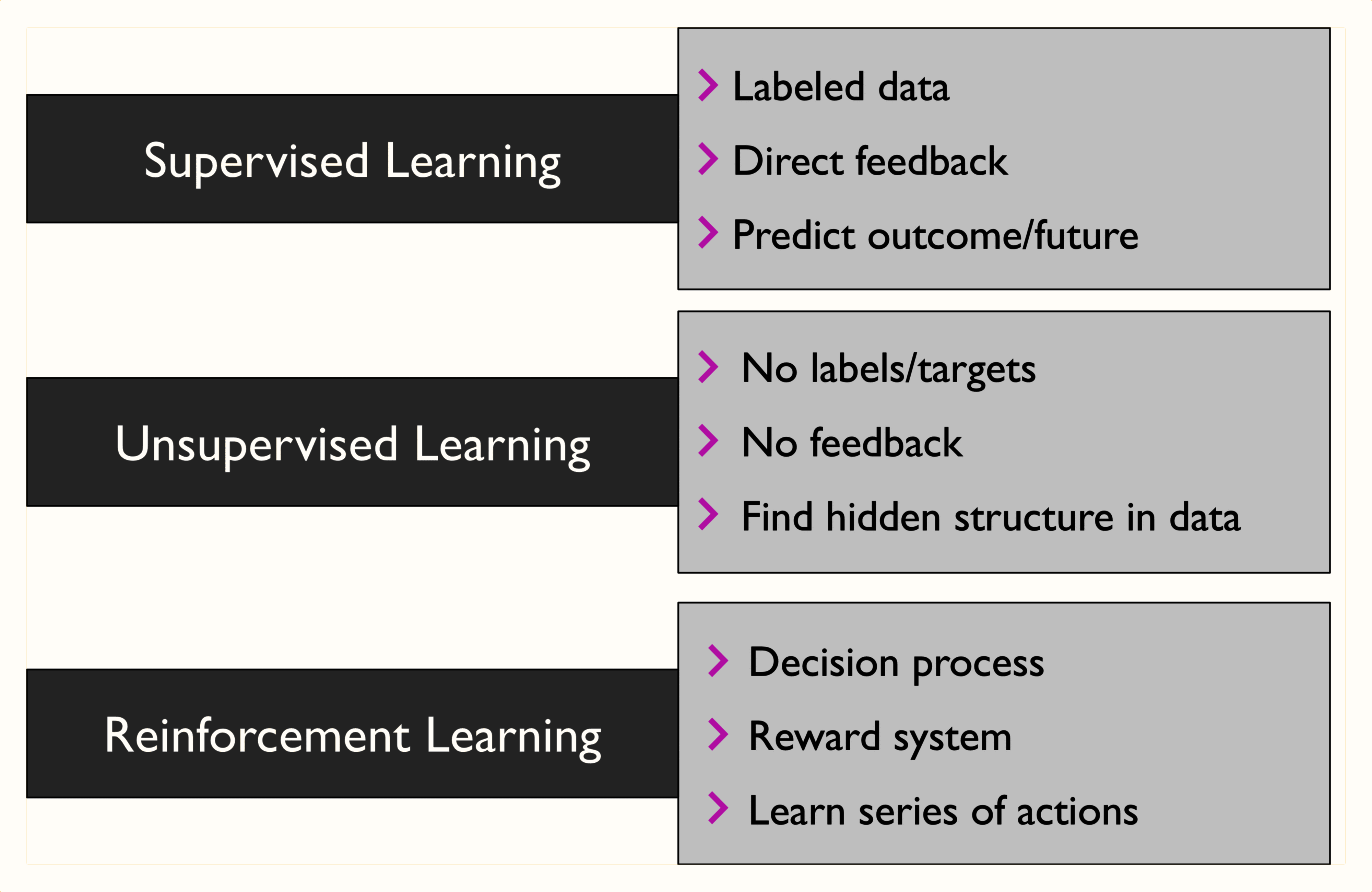
监督式学习 (Supervised Learning)
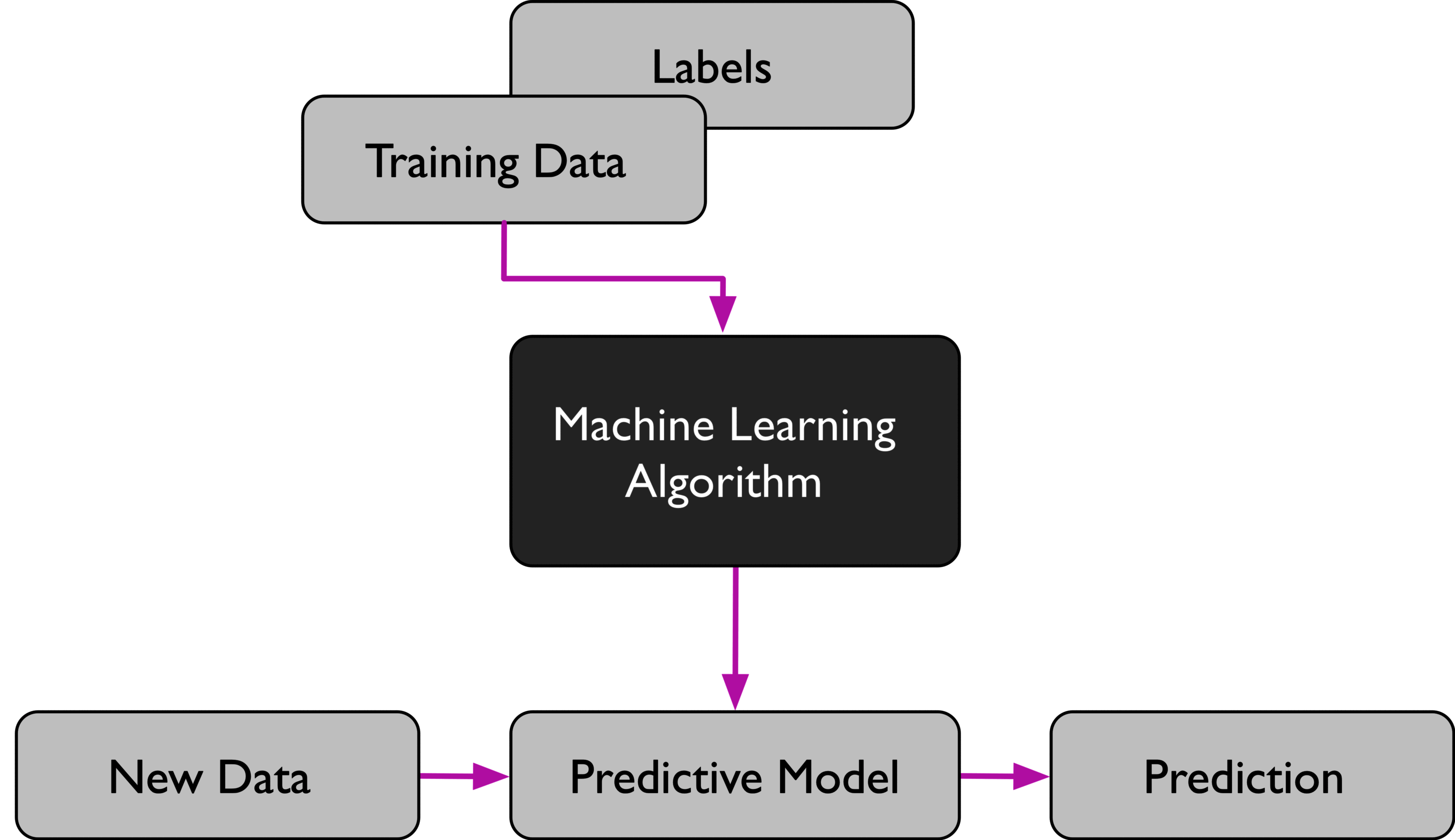
监督式学习,是一个机器学习中的方法,可以由训练资料中学到或建立一个模式,并依此模式推测新的实例。训练资料是由输入物件 (通常是向量) 和预期输出所组成。函数的输出可以是一个连续的值 (称为回归分析),或是预测一个分类标签 (称为分类)。
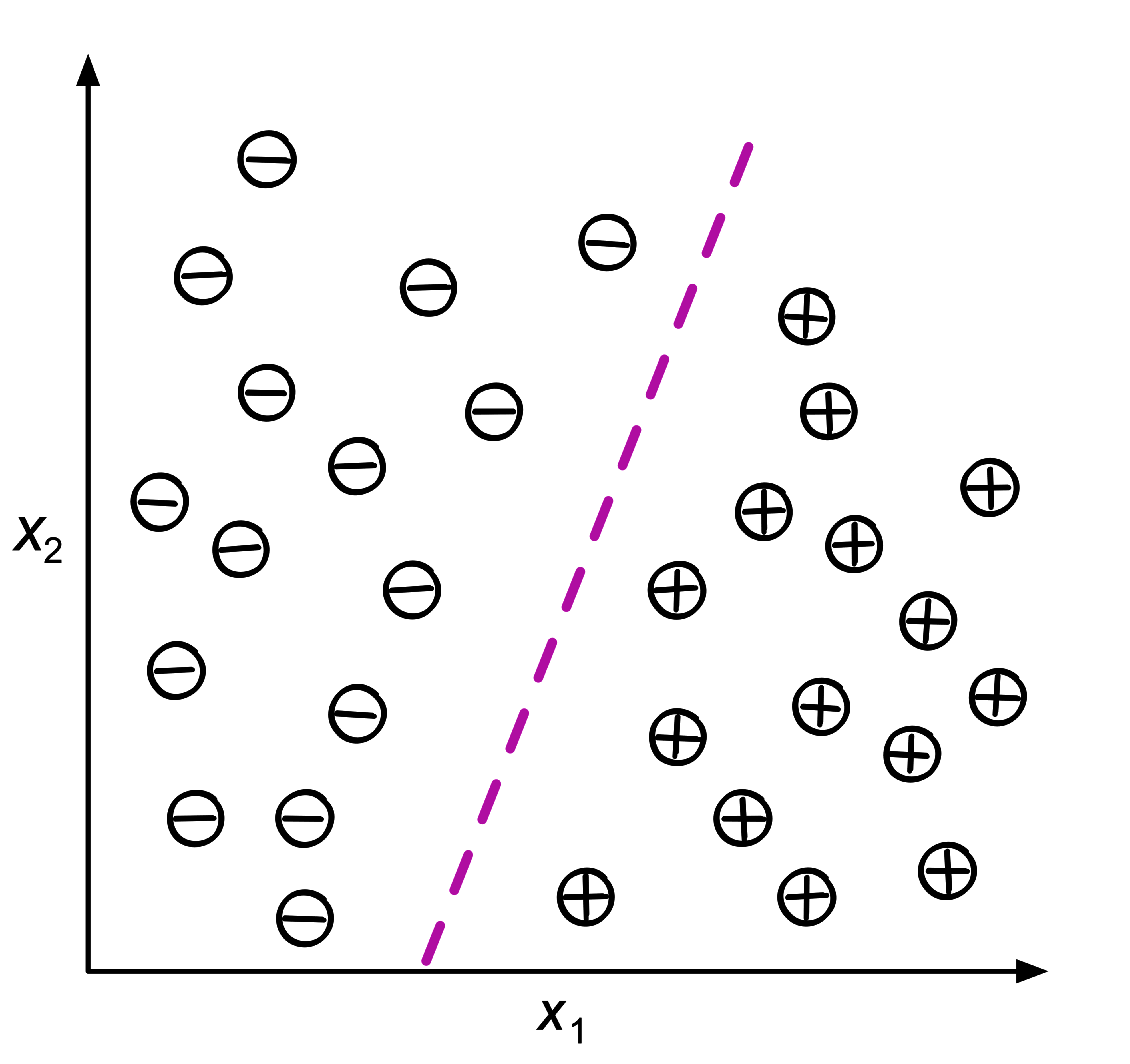
分类 (Classification)
在分类中,函数的输出是一个分类标签。常见的例子有垃圾邮件识别和手写数字识别。
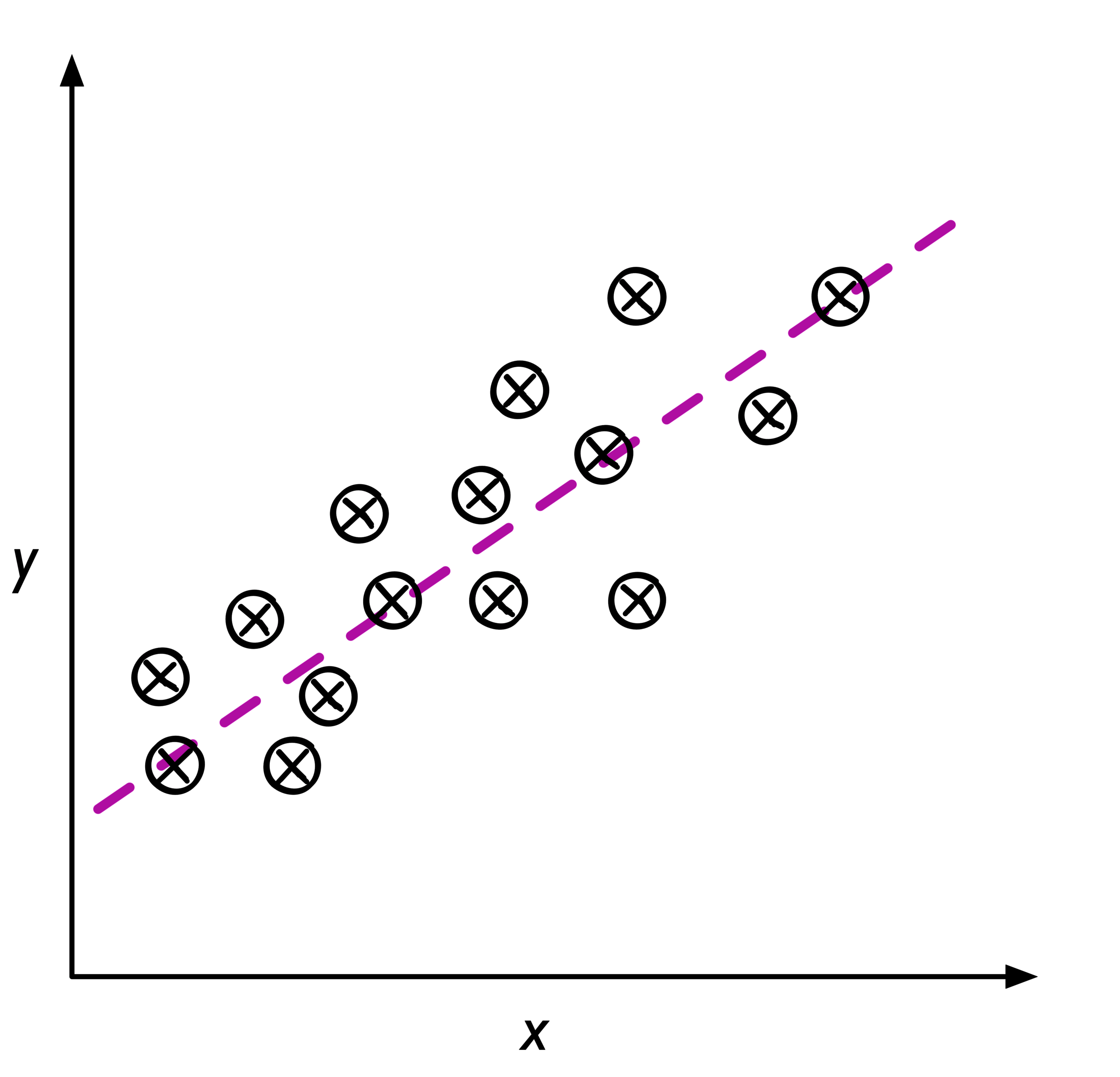
回归 (Regression)
在回归中,函数的输出可以是一个连续的值,通常是一个数学函数。例如,对于某一职位,员工薪水和工龄之间的关系。
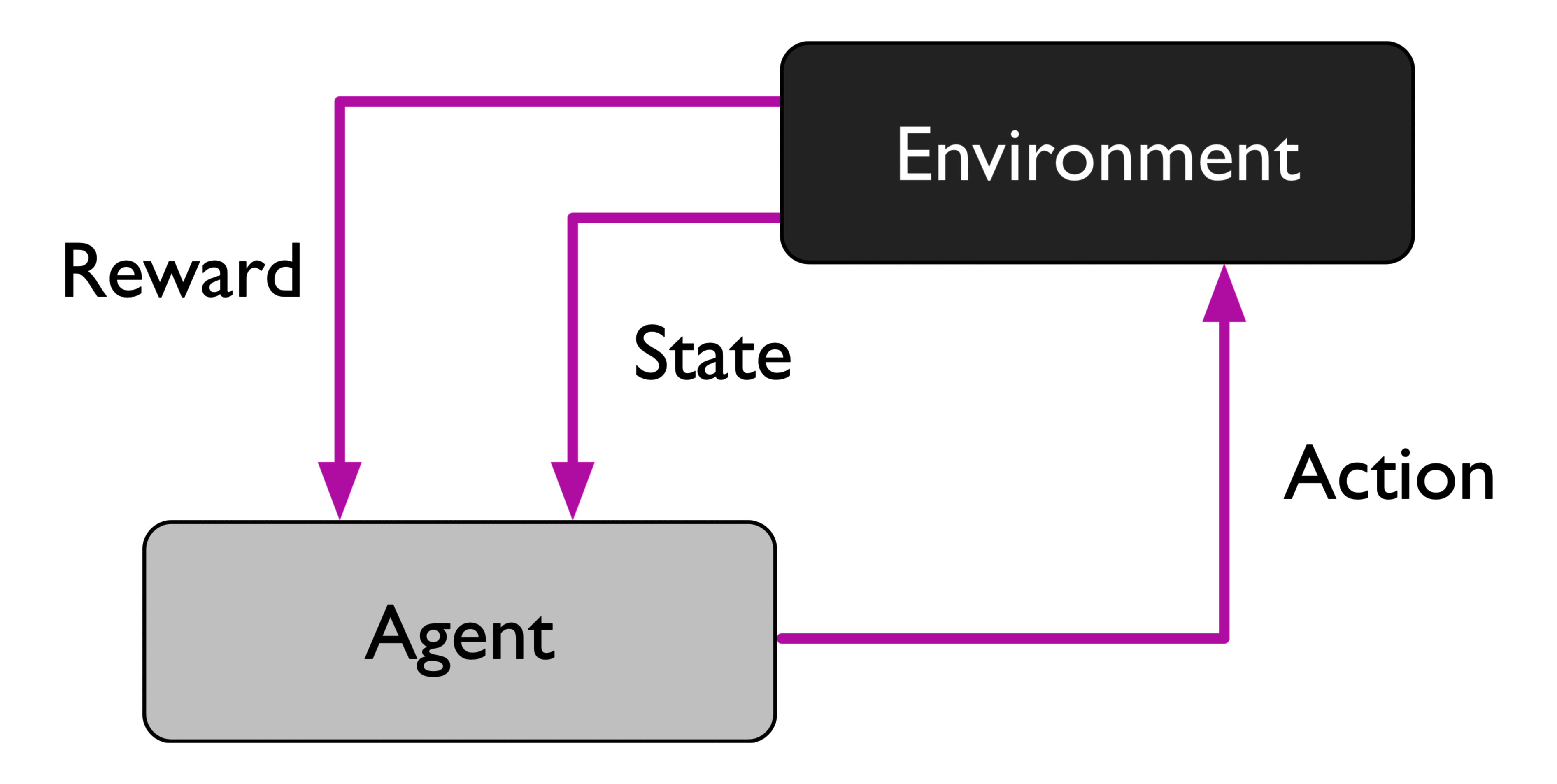
强化学习 (Reinforcement Learning)
另一种类型的机器学习是强化学习。在强化学习中,目标是开发一种基于与环境交互来改善其性能的代理。由于存在反馈机制,因此可以认为强化学习和监督式学习相关。然而,在强化学习中,这种反馈不是正确标签,而是强调如何基于环境而行动,以取得最大化的预期利益。
一个普遍的例子是象棋引擎。在这里,代理根据棋盘状态 (环境) 决定一系列动作,反馈可以在游戏结束时定义为胜或负。
非监督式学习 (Unsupervised Learning)
在无监督学习中,我们处理的是未标记的数据或未知结构的数据。使用无监督的学习技术,我们能够探索我们的数据的结构,以提取有意义的信息。常见的非监督式学习方法有聚类分析和降维。
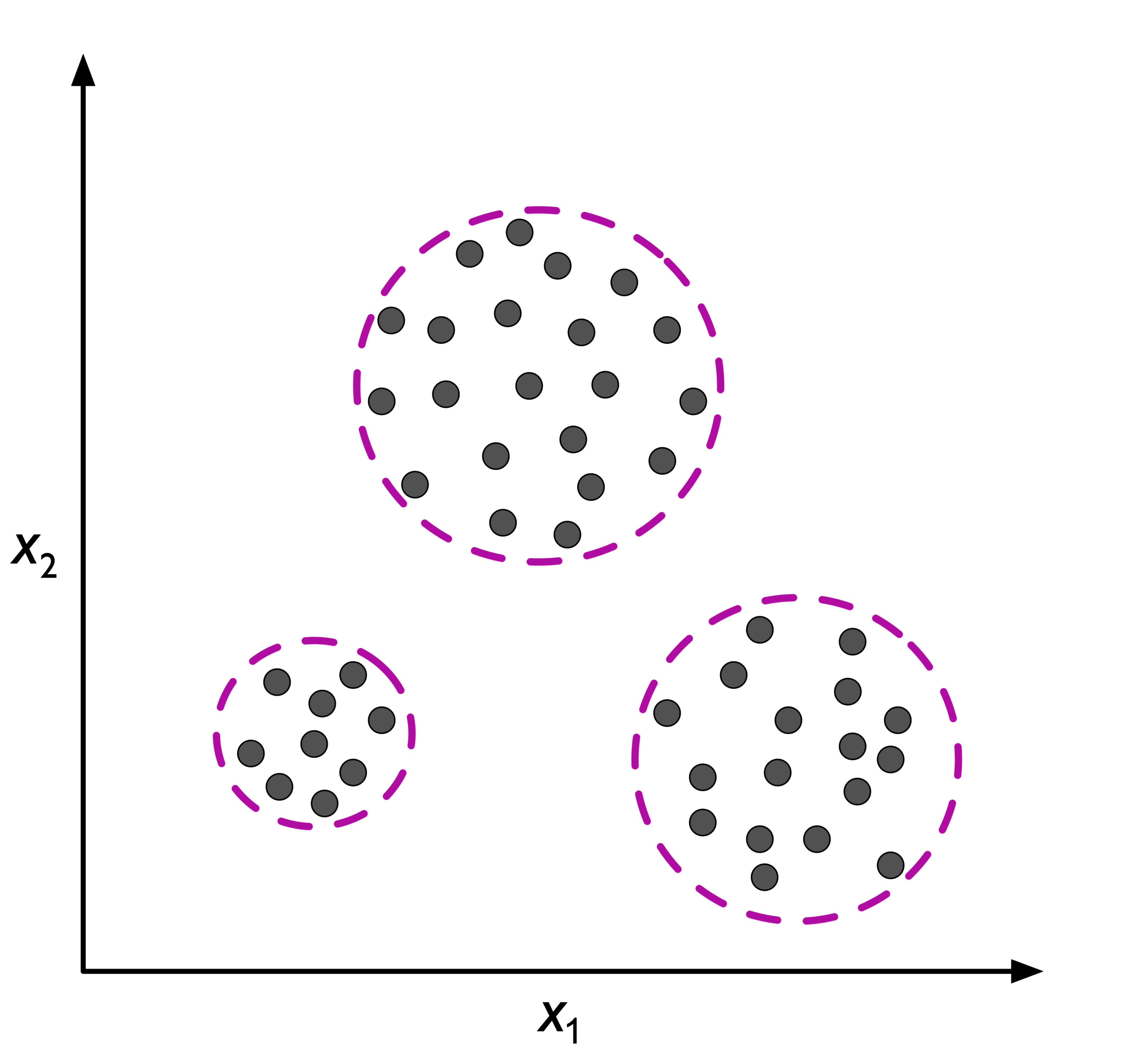
聚类 (Clustering)
聚类是一种探索性数据分析技术,能够在不知道输入对象的任何先验知识的情况下,将其分成不同的集群。每个集群包含一定程度相似的对象,但是与其他集群中的对象不相似。例如营销人员将客户分类成不同的客户群。
降维 (Dimensionality Reduction)
通常,我们正在处理高维度的数据,这对于有限的存储空间和机器学习算法的计算性能是很大的挑战。降维是指在某些限定条件下,降低随机变量的维度,得到一组“不相关”的主变量,同时保留大部分有效信息。
