特征的重要性
避免过拟合的方法中,有一种称为特征选择 (Feature Selection),即选择最重要的特征、同时舍弃不重要的特征。本文以 Wine 数据集为例,使用随机森林演示了特征重要性评估和选择方法。
Wine 数据集
Wine 数据集是对意大利同一地区种植的葡萄酒进行化学分析的结果,但起源于三种不同的品种。
第一列为其分类标签 (即葡萄酒产地),其余 13 列为特征。
import pandas as pd
df_wine = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",
header=None,
)
df_wine.columns = [
"Class label",
"Alcohol",
"Malic acid",
"Ash",
"Alcalinity of ash",
"Magnesium",
"Total phenols",
"Flavanoids",
"Nonflavanoid phenols",
"Proanthocyanins",
"Color intensity",
"Hue",
"OD280/OD315 of diluted wines",
"Proline",
]
print(df_wine.head())
按分类标签分割数据集为 70% 的训练数据集和 30% 的测试数据集:
from sklearn.model_selection import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0, stratify=y
)
特征重要性的 Scikit-learn 实现
scikit-learn 中的 sklearn.ensemble.RandomForestClassifier 已经集成了特征的重要性排序,实现如下:
from sklearn.ensemble import RandomForestClassifier
feat_labels = df_wine.columns[1:]
forest = RandomForestClassifier(n_estimators=500, random_state=1)
forest.fit(X_train, y_train)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print("{:2d}) {:30}{:f} ".format(f + 1, feat_labels[f], importances[f]))
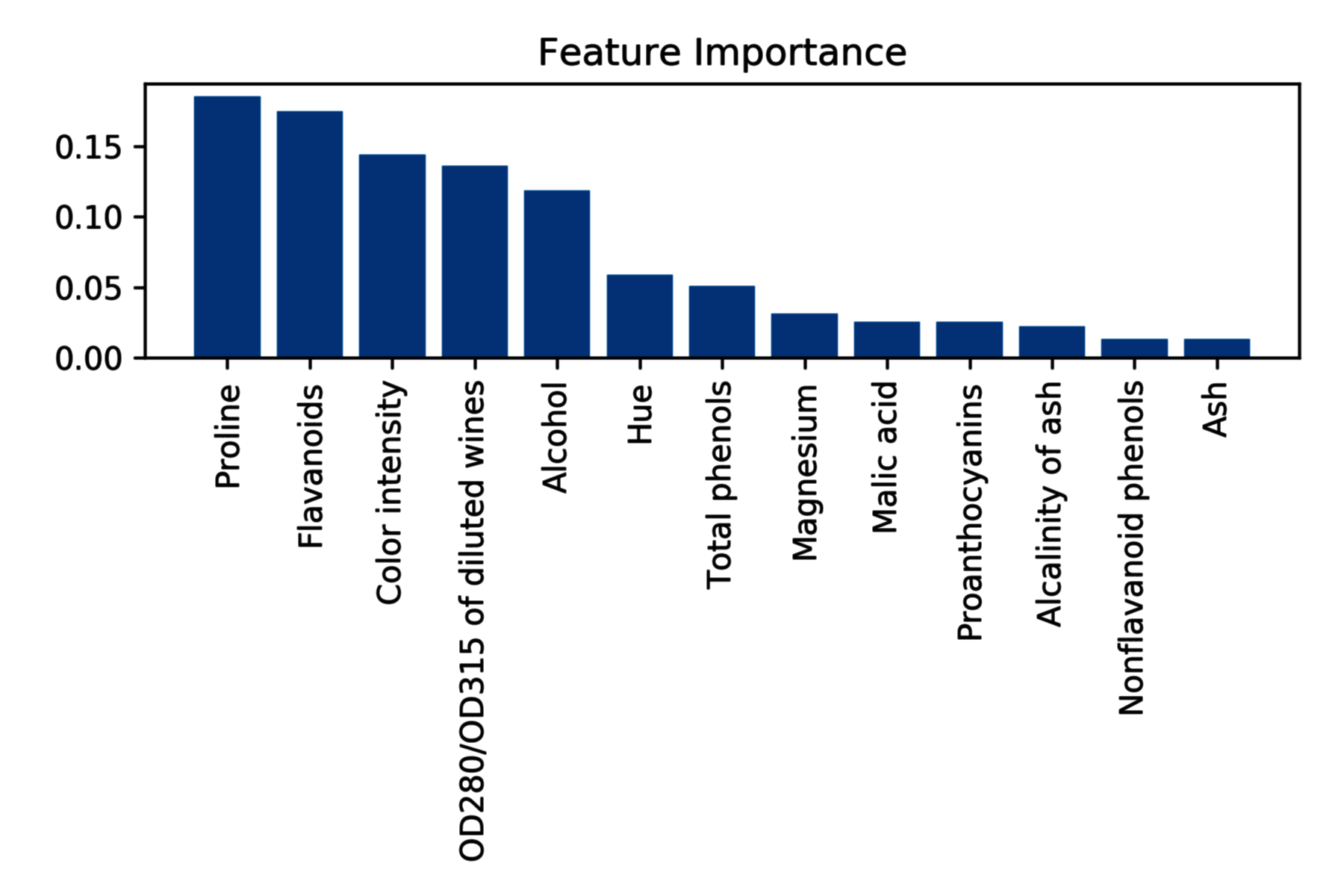
特征的重要性排序如下:
1) Proline 0.179927
2) Color intensity 0.153158
3) Flavanoids 0.146123
4) Alcohol 0.138224
5) OD280/OD315 of diluted wines 0.114818
6) Hue 0.077525
7) Total phenols 0.058236
8) Malic acid 0.030856
9) Alcalinity of ash 0.030000
10) Proanthocyanins 0.025713
11) Magnesium 0.025135
12) Nonflavanoid phenols 0.011548
13) Ash 0.008738
对特征重要性进行绘图:
import matplotlib.pyplot as plt
plt.title("Feature Importance")
plt.bar(range(X_train.shape[1]), importances[indices], align="center")
plt.xticks(range(X_train.shape[1]), feat_labels, rotation=90)
plt.xlim([-1, X_train.shape[1]])
plt.tight_layout()
plt.show()
需要提到的是,scikit-learn 还实现了一个 SelectFromModel 对象,它在模型拟合之后根据用户指定的阈值选择特征,并且可以将不同估计器 (Estimator) 与其连接。
以随机森林为例,以使用以下代码将特征阈值设置为 0.1,可以筛选出最重要的五个特征:
from sklearn.feature_selection import SelectFromModel
sfm = SelectFromModel(forest, threshold=0.1, prefit=True)
X_selected = sfm.transform(X_train)
print("Number of samples that meet this criterion:", X_selected.shape[0])
for f in range(X_selected.shape[1]):
print(
"{:2d}) {:30}{:f} ".format(
f + 1, feat_labels[indices[f]], importances[indices[f]]
)
)
输出如下:
Number of samples that meet this criterion: 124
1) Proline 0.179927
2) Color intensity 0.153158
3) Flavanoids 0.146123
4) Alcohol 0.138224
5) OD280/OD315 of diluted wines 0.114818