机器学习主要包括预处理、学习、评估和预测等阶段,本文进行概览说明。
预处理 (Preprocessing)
原始数据很少呈现为学习算法的最佳性能所需的形式和形状。因此,数据的预处理是任何机器学习应用程序中最关键的步骤之一。以鸢尾花数据集为例,我们可以将原始数据看作一系列花图,从中我们可以提取有意义的特征,如花的颜色,花萼和花瓣的长度和宽度。
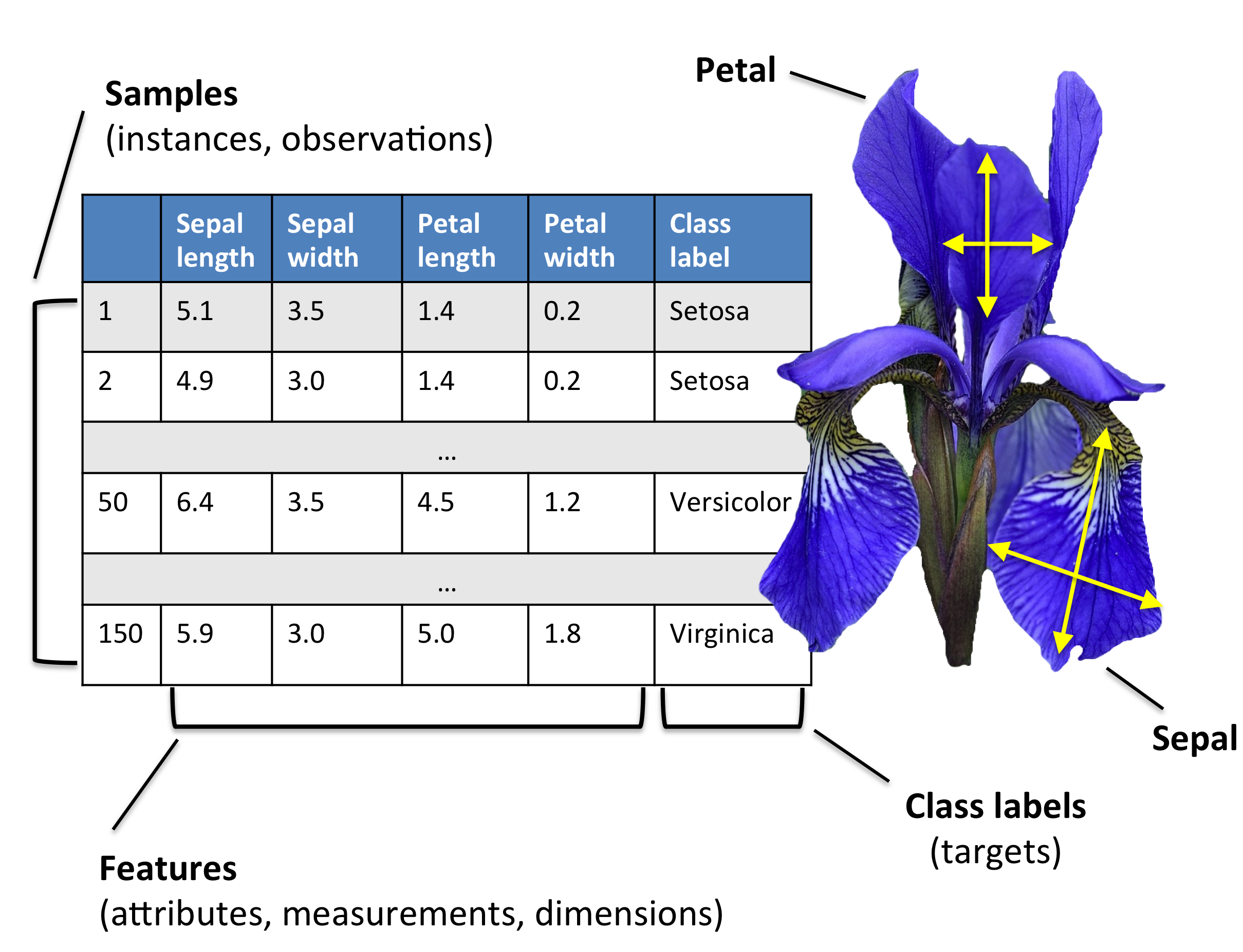
许多机器学习算法还要求能够将所有特征在同一数量级,这通常通过归一化或者正态分布等特征变换方法来实现。
部分特征可能是高度相关的,具有特征冗余。在这种情况下,降维可以减少所需的存储空间,并且算法可以学习得更快。
为了确定机器学习算法是否不仅在训练集上表现良好的同时,能很好地预测到新的数据,我们将数据集随机分为相互独立的训练集和测试集。训练集用于训练和优化我们的机器学习模型,测试集用于最终评估最终模型。
学习 (Learning)
目前已有许多不同的机器学习算法,用于解决不同的问题任务。每个分类算法都有其固有的偏差,在实践中,比较几个不同的算法然后从中选出最优算法,对于训练和选择最佳性能模型至关重要。一个常用的算法度量指标是分类准确率,即正确分类数据的比重。
另外,我们可以使用不同的交叉验证技术,其中将训练数据集进一步分为训练和验证子集,以估计模型的泛化性能。
最后,算法的默认参数对于实际问题往往不会具有最佳表现。因此,我们可以使用超参数优化技术,通过调节算法参数,我们可以提高算法的性能。
评估和预测 (Evaluation & Prediction)
在选择了模型并使用训练集进行训练之后,我们可以使用测试集来来估计泛化误差。
如果我们对其性能感到满意,可以使用这个模型来预测新的未来数据。
需要注意的是,训练的参数(如特征缩放和降维)仅从训练数据集中获得,在测试数据上测量的性能可能是过拟合的。